3 Eksploracyjna analiza danych nieprzestrzennych
library('sp')
library('ggplot2')
library('corrplot')
library('geostatbook')
data(punkty)
data(granica)3.1 Cele eksploracyjnej analizy danych
Zazwyczaj przed przystąpieniem do analiz geostatystycznych koniecznie jest wykonanie eksploracyjnej analizy danych nieprzestrzennych. Jej ogólne cele obejmują:
- Stworzenie ogólnej charakterystyki danych oraz badanego zjawiska
- Określenie przestrzennego/czasowego typu próbkowania
- Uzyskanie informacji o relacji pomiędzy lokalizacją obserwacji a czynnikami wpływającymi na zmienność przestrzenną badanych cech
3.2 Dane
3.2.1 Dane
Nie istnieje jedyna, optymalna ścieżka eksploracji danych. Proces ten różni się w zależności od posiadanego zbioru danych, jak i od postawionego pytania. Warto jednak, aby jednym z pierwszych kroków było przyjrzenie się danym wejściowym. Pozwala na to, między innymi, funkcja str(). Przykładowo, dla obiektu klasy SpatialPointsDataFrame wyświetla ona szereg ważnych informacji. Oprócz klasy można również odczytać, że obiekt punkty zawiera pięć elementów (ang. slots) rozpoczynających się od symbolu @. Pierwszy z nich, @data jest obiektem klasy data.frame zawierającym informacje o kolejnych punktach w tym zbiorze. Element @coords.nrs określa numer kolumn zawierających współrzędne w oryginalnym zbiorze danych. W poniższym przypadku żadna kolumna nie ma takich informacji. Kolejny element, @coords definiuje współrzędne kolejnych punktów w obiekcie punkty. Ostatnie dwa elementy, @bbox i @proj4string określają kolejno zasięg przestrzenny danych oraz definicję ich układu współrzędnych.
str(punkty)## Formal class 'SpatialPointsDataFrame' [package "sp"] with 5 slots
## ..@ data :'data.frame': 250 obs. of 5 variables:
## .. ..$ srtm: num [1:250] 231 185 269 212 209 ...
## .. ..$ clc : num [1:250] 1 1 1 1 2 2 2 2 1 1 ...
## .. ..$ temp: num [1:250] 22.5 16 16.1 17.1 22.3 ...
## .. ..$ ndvi: num [1:250] 0.589 0.546 0.509 0.529 0.491 ...
## .. ..$ savi: num [1:250] 0.357 0.382 0.342 0.345 0.22 ...
## ..@ coords.nrs : num(0)
## ..@ coords : num [1:250, 1:2] 753638 749498 750131 751764 753676 ...
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ : NULL
## .. .. ..$ : chr [1:2] "x" "y"
## ..@ bbox : num [1:2, 1:2] 745547 712619 756937 721193
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ : chr [1:2] "x" "y"
## .. .. ..$ : chr [1:2] "min" "max"
## ..@ proj4string:Formal class 'CRS' [package "sp"] with 1 slot
## .. .. ..@ projargs: chr "+init=epsg:2180 +proj=tmerc +lat_0=0 +lon_0=19 +k=0.9993 +x_0=500000 +y_0=-5300000 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m"| __truncated__Oczywiście, każdy z elementów można obejrzeć indywidualnie, poprzez połączenie nazwy obiekty, znaku @, oraz nazwy elementu. Przykładowo punkty@data pozwala na obejrzenie tabeli atrybutów zbioru punktowego.
str(punkty@data)## 'data.frame': 250 obs. of 5 variables:
## $ srtm: num 231 185 269 212 209 ...
## $ clc : num 1 1 1 1 2 2 2 2 1 1 ...
## $ temp: num 22.5 16 16.1 17.1 22.3 ...
## $ ndvi: num 0.589 0.546 0.509 0.529 0.491 ...
## $ savi: num 0.357 0.382 0.342 0.345 0.22 ...Istnieją dwa sposoby uzyskania wartości wybranej zmiennej z tabeli atrybutów.
punkty@data$temp #1
punkty$temp #2Z uwagi na to, że zajmujemy się danymi przestrzennymi - warto też się upewnić czy dane zostały poprawnie wczytane i obejmują analizowany obszar. Najszybciej można to wykonać z pomocą funkcji plot().
plot(punkty)
plot(granica, add=TRUE)
3.3 Statystyki opisowe
3.3.1 Statystyki opisowe
Podstawową funkcją w R służącą wyliczaniu podstawowych statystyk jest summary(). Dla zmiennych numerycznych wyświetla ona wartość minimalną, pierwszy kwartyl, medianę, średnią, trzeci kwartyl, oraz wartość maksymalną.
summary(punkty@data)## srtm clc temp ndvi
## Min. :146.2 Min. :1.000 Min. : 8.706 Min. :0.2102
## 1st Qu.:191.0 1st Qu.:1.000 1st Qu.:13.284 1st Qu.:0.4567
## Median :218.2 Median :1.000 Median :15.309 Median :0.5037
## Mean :213.4 Mean :1.268 Mean :15.950 Mean :0.5039
## 3rd Qu.:236.4 3rd Qu.:1.000 3rd Qu.:18.273 3rd Qu.:0.5521
## Max. :278.8 Max. :4.000 Max. :26.139 Max. :0.6848
## savi
## Min. :0.08343
## 1st Qu.:0.29017
## Median :0.32212
## Mean :0.31847
## 3rd Qu.:0.35292
## Max. :0.483543.3.2 Statystyki opisowe | średnia i mediana
Do określenia wartości przeciętnej zmiennych najczęściej stosuje się medianę i średnią.
median(punkty$temp, na.rm=TRUE)## [1] 15.30944mean(punkty$temp, na.rm=TRUE)## [1] 15.95036- W wypadku symetrycznego rozkładu te dwie cechy są równe
- Średnia jest bardziej wrażliwa na wartości odstające
- Mediana jest lepszą miarą środka danych, jeżeli są one skośne
Po co używać średniej?
- Bardziej przydatna w przypadku małych zbiorów danych
- Gdy rozkład danych jest symetryczny
- (Jednak) często warto podawać obie miary
3.3.3 Statystyki opisowe | minimum i maksimum
Minimalna i maksymalna wartość zmiennej służy do określenia ekstremów w zbiorze danych, jak i sprawdzenia zakresu wartości.
min(punkty$temp, na.rm=TRUE)## [1] 8.706485max(punkty$temp, na.rm=TRUE)## [1] 26.139473.3.4 Statystyki opisowe | odchylenie standardowe
Dodatkowo, często używaną statystyką jest odchylenie standardowe. Wartość ta określa w jak mocno wartości zmiennej odstają od średniej. Dla rozkładu normalnego ta wartość ma znane własności:
- 68% obserwacji mieści się w granicach jednego odchylenia standardowego od średniej
- 95% obserwacji mieści się w granicach dwóch odchyleń standardowych od średniej
- 99,7% obserwacji mieści się w granicach trzech odchyleń standardowych od średniej

sd(punkty$temp, na.rm=TRUE)## [1] 3.8395963.4 Wykresy
3.4.1 Histogram
Histogram należy do typów wykresów najczęściej używanych w eksploracyjnej analizie danych.
ggplot(punkty@data, aes(temp)) + geom_histogram()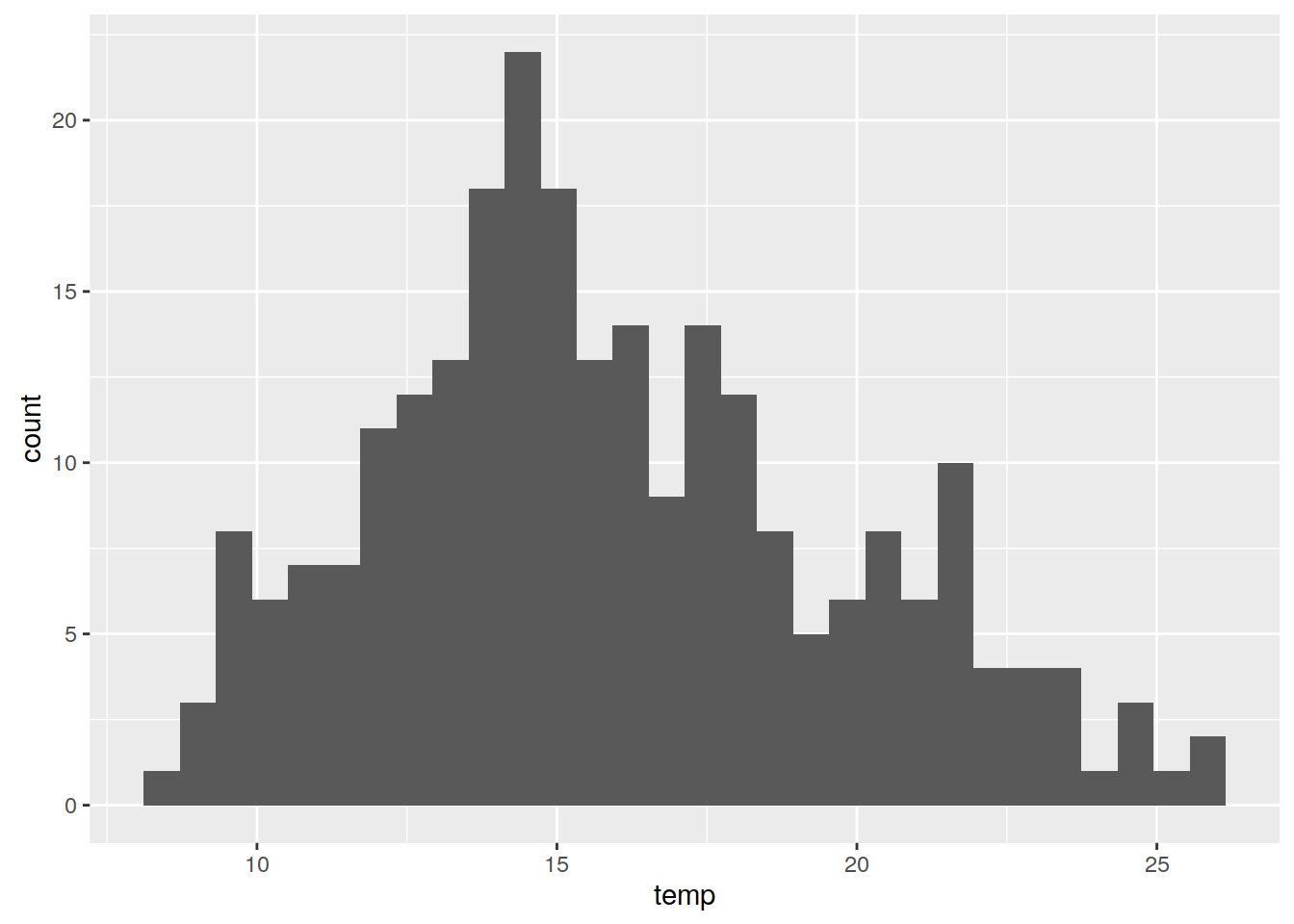
- Stworzony przez Karla Pearsona
- Jest graficzną reprezentacją rozkładu danych
- Wartości danych są łączone w przedziały (na osi poziomej) a na osi pionowej jest ukazana liczba punktów (obserwacji) w każdym przedziale
- Różny dobór przedziałów może dawać inną informację
- W pakiecie
ggplot2, domyślnie przedział jest ustalany poprzez podzielenie zakresu wartości przez 30
3.4.2 Estymator jądrowy gęstości (ang. kernel density estimation)
Podobną funkcję do histogramu spełnia estymator jądrowy gęstości. Przypomina on wygładzony wykres histogramu i również służy graficznej reprezentacji rozkładu danych.
ggplot(punkty@data, aes(temp)) + geom_density()
3.4.3 Wykres kwantyl-kwantyl (ang.quantile-quantile)
Wykres kwantyl-kwantyl ułatwia interpretację rozkładu danych.
ggplot(punkty@data, aes(sample=temp)) + stat_qq()
Na poniższej rycinie można zobaczyć przykłady najczęściej spotykanych cech rozkładu danych w wykresach kwantyl-kwantyl.

3.4.4 Dystrybuanta (CDF)
Dystrybuanta (ang. conditional density function - CDF) wyświetla prawdopodobieństwo, że wartość zmiennej przewidywanej jest mniejsza lub równa określonej wartości
ggplot(punkty@data, aes(temp)) + stat_ecdf()
3.5 Porównanie zmiennych
Wybór odpowiedniej metody porównania zmiennych zależy od szeregu cech, między innymi liczby zmiennych, ich typu, rozkładu wartości, etc.
3.5.1 Kowariancja
Kowariancja jest nieunormowaną miarą zależności liniowej pomiędzy dwiema zmiennymi. Kowariancja dwóch zmiennych \(x\) i \(y\) pokazuje jak dwie zmienne są ze sobą liniowo powiązane. Dodatnia kowariancja wskazuje na pozytywną relację liniową pomiędzy zmiennymi, podczas gdy ujemna kowariancja świadczy o odwrotnej sytuacji. Jeżeli zmienne nie są ze sobą liniowo powiązane, wartość kowariacji jest bliska zeru. Inaczej mówiąc, kowariancja stanowi miarę wspólnej zmienności dwóch zmiennych. Wielkość samej kowariancji uzależniona jest od przyjętej skali zmiennej (jednostki). Inne wyniku uzyskamy (przy tej samej zależności pomiędzy parą zmiennych), gdy będziemy analizować wyniki np. wysokości terenu w metrach i temperatury w stopniach Celsjusza a inne dla wysokości terenu w metrach i temperatury w stopniach Fahrenheita. Do wyliczania kowariancji w R służy funkcja cov().
cov(punkty$temp, punkty$ndvi)## [1] 0.020475093.5.2 Współczynnik korelacji
Współczynnik korelacji to unormowana miara zależności pomiędzy dwiema zmiennymi, przyjmująca wartości od -1 do 1. Ten współczynnik jest uzyskiwany poprzez podzielenie wartości kowariancji przez odchylenie standardowe wyników. Z racji unormowania nie jest ona uzależniona od jednostki. Korelację można wyliczyć dzięki funkcji cor(). Działa ona zarówno w przypadku dwóch zmiennych numerycznych, jak i całego obiektu zawierającego zmienne numeryczne.
ggplot(punkty@data, aes(temp, ndvi)) + geom_point()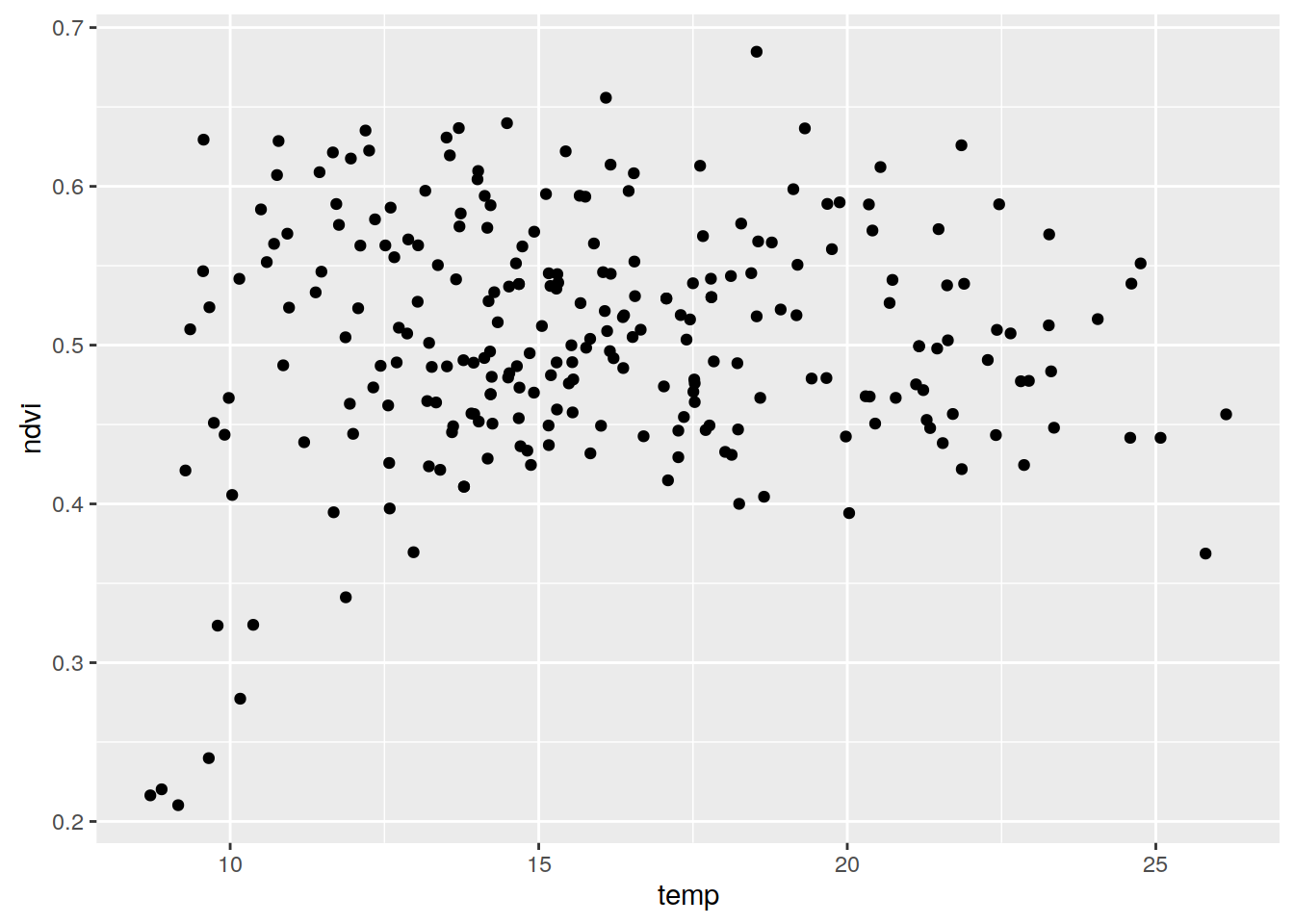
cor(punkty$temp, punkty$ndvi)## [1] 0.07049136cor(punkty@data[c(1, 3:5)])## srtm temp ndvi savi
## srtm 1.00000000 -0.060458939 0.05230326 0.035760652
## temp -0.06045894 1.000000000 0.07049136 -0.007748702
## ndvi 0.05230326 0.070491358 1.00000000 0.889037014
## savi 0.03576065 -0.007748702 0.88903701 1.000000000Dodatkowo funkcja cor.test() służy do testowania istotności korelacji. Za pomocą argumentu method można również wybrać jedną z trzech dostępnych miar korelacji.
cor.test(punkty$temp, punkty$ndvi)##
## Pearson's product-moment correlation
##
## data: punkty$temp and punkty$ndvi
## t = 1.1129, df = 248, p-value = 0.2668
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.05404834 0.19287158
## sample estimates:
## cor
## 0.07049136W przypadku posiadania co najmniej kilku par zmiennych, można również skorzystać z funkcji corrplot() z pakietu corrplot. Wyświetla ona wykres pokazujący wartości korelacji pomiędzy kolejnymi zmiennymi.
corrplot(cor(punkty@data[c(1, 3:5)]))
3.5.3 Wykres pudełkowy
Wykres pudełkowy obrazuje pięć podstawowych statystyk opisowych oraz wartości odstające. Pudełko to zakres międzykwantylowy (IQR), a linie oznaczają najbardziej ekstremalne wartości, ale nie odstające. Górna z nich to 1,5*IQR ponad krawędź pudełka, dolna to 1,5*IQR poniżej wartości dolnej krawędzi pudełka. Linia środkowa to mediana.
punkty$clc <- as.factor(punkty$clc)
ggplot(punkty@data, aes(clc, temp)) + geom_boxplot()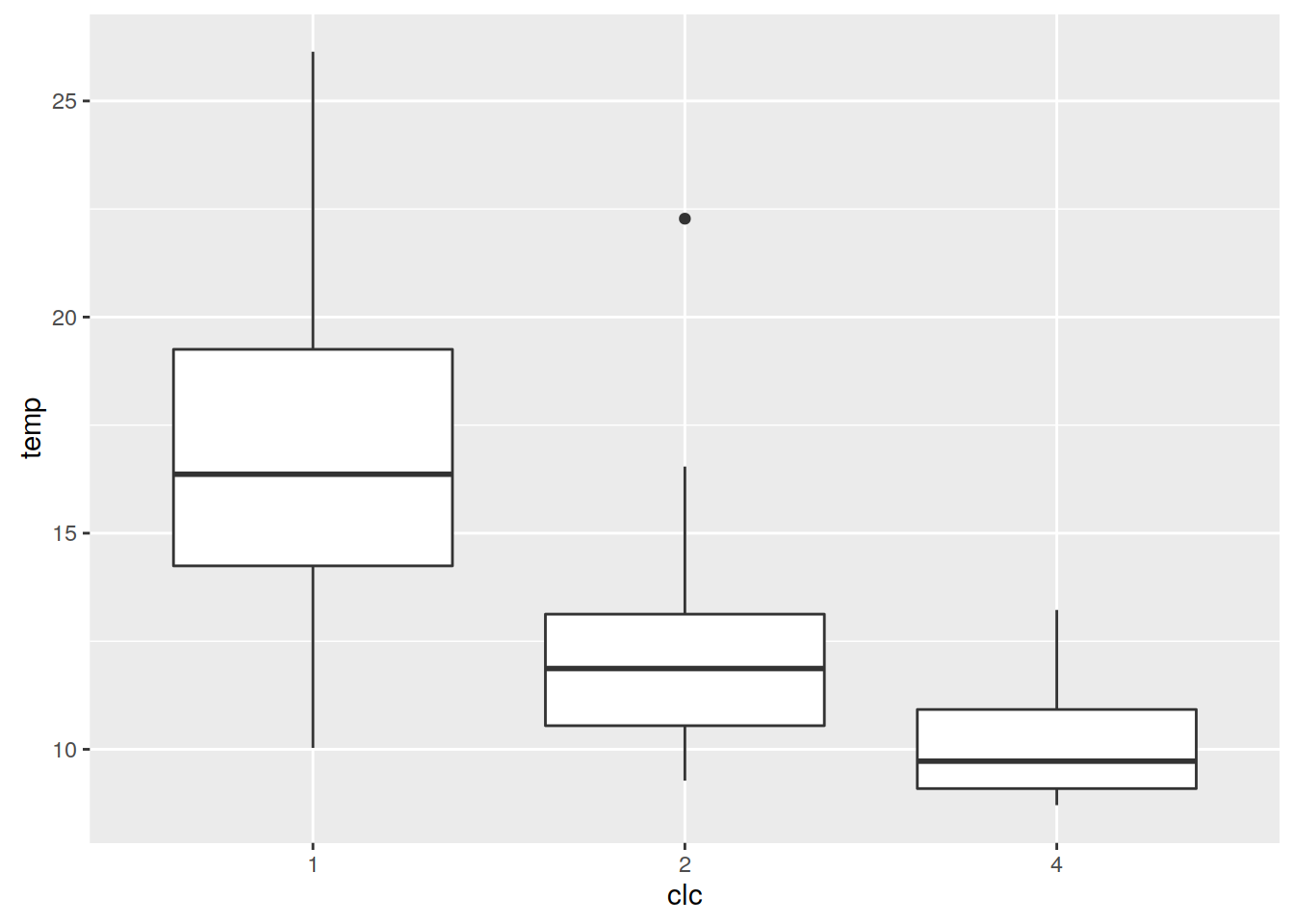
3.5.4 Testowanie istotności różnić średniej pomiędzy grupami
Analiza wariancji (ang. Analysis of Variance - ANOVA) służy do testowania istotności różnic między średnimi w wielu grupach. Metoda ta służy do oceny czy średnie wartości cechy \(Y\) różnią się istotnie pomiędzy grupami wyznaczonymi przez zmienną \(X\). ANOVA nie pozwala na stwierdzenie między którymi grupami występują różnice. Aby to stwierdzić konieczne jest wykonanie porównań wielokrotnych (post-hoc). ANOVĘ można wykonać za pomocą funkcji aov() definiując zmienną zależną oraz zmienną grupującą oraz zbiór danych.
punkty$clc <- as.factor(punkty$clc)
aov_test <- aov(temp~clc, data=punkty)
summary(aov_test)## Df Sum Sq Mean Sq F value Pr(>F)
## clc 2 1056 528.0 49.87 <2e-16 ***
## Residuals 247 2615 10.6
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## null device
## 1Do wykonania porównań wielokrotnych służy funkcja TukeyHSD(). Dodatkowo wyniki można wizualizować za pomocą funkcji plot().
tukey <- TukeyHSD(aov_test, 'clc')
plot(tukey, las=1)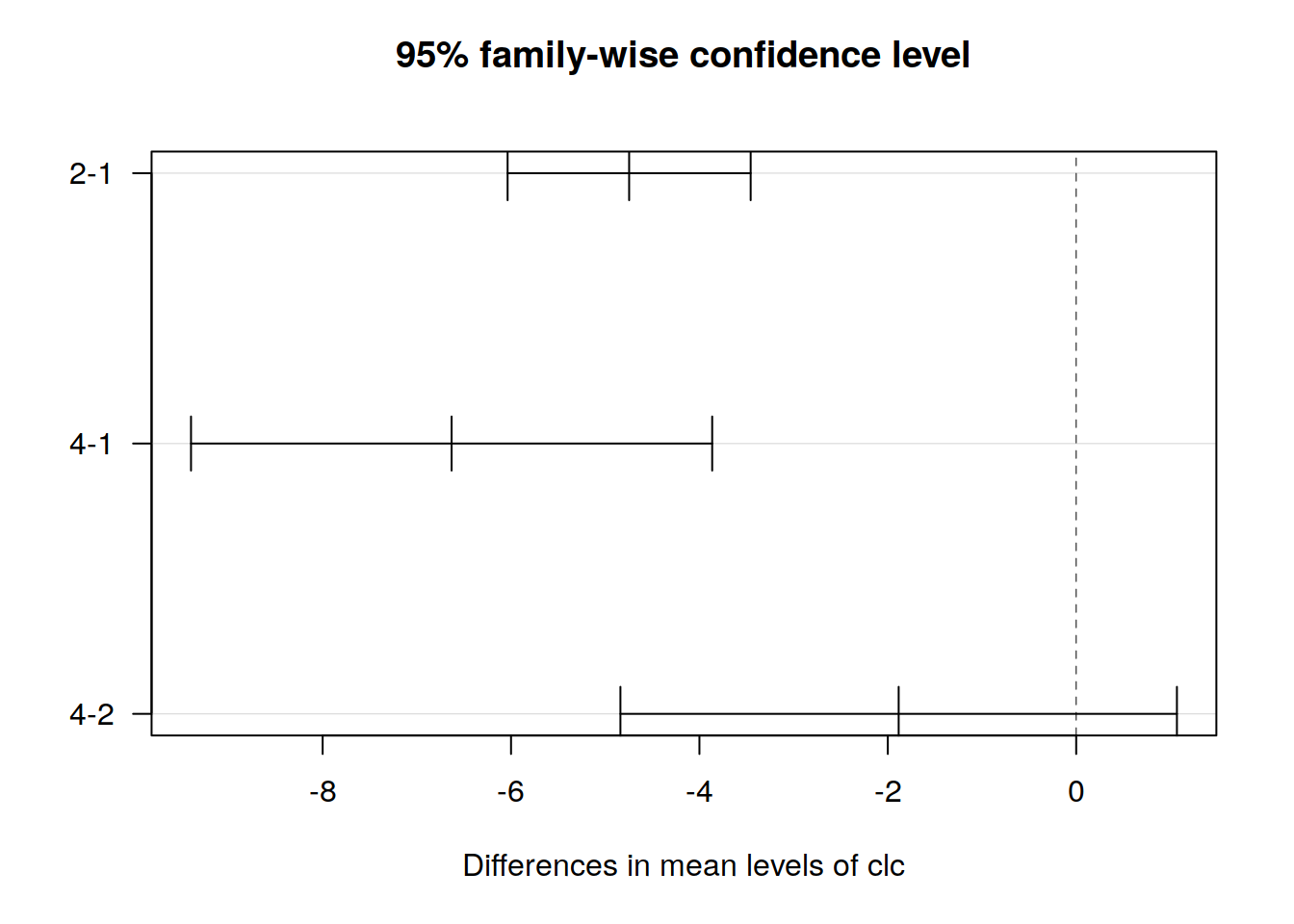
3.6 Transformacje danych
3.6.1 Transformacje danych
Transformacja danych może mieć na celu ułatwienie porównywania różnych zmiennych, zniwelowanie skośności rozkładu lub też zmniejszenie wpływu danych odstających.
3.6.2 Transformacja danych | Standaryzacja
Centrowanie i skalowanie (standaryzacja):
- Centrowanie danych - wybierana jest przeciętna wartość predyktora, a następnie od wszystkich wartości predyktorów odejmowana jest wybrana wcześniej wartość
- Skalowanie danych - dzielenie każdej wartości predyktora przez jego odchylenie standardowe
- Wadą tego podejścia jest główne zmniejszenie interpretowalności pojedynczych wartości
3.6.3 Transformacja danych | Centrowanie
ggplot(punkty@data, aes(temp)) + geom_density()
punkty$temp_center <- punkty$temp - mean(punkty$temp)
ggplot(punkty@data, aes(temp_center)) + geom_density()
3.6.4 Transformacja danych | Skalowanie
ggplot(punkty@data, aes(temp)) + geom_density()
punkty$temp_scale <- punkty$temp / sd(punkty$temp)
ggplot(punkty@data, aes(temp_scale)) + geom_density()
3.6.5 Transformacja danych | Standaryzacja
Do standaryzacji (centrowanie i skalowanie) służy funkcja scale().
ggplot(punkty@data, aes(temp)) + geom_density()
punkty$temp_standard <- scale(punkty$temp)
ggplot(punkty@data, aes(temp_standard)) + geom_density()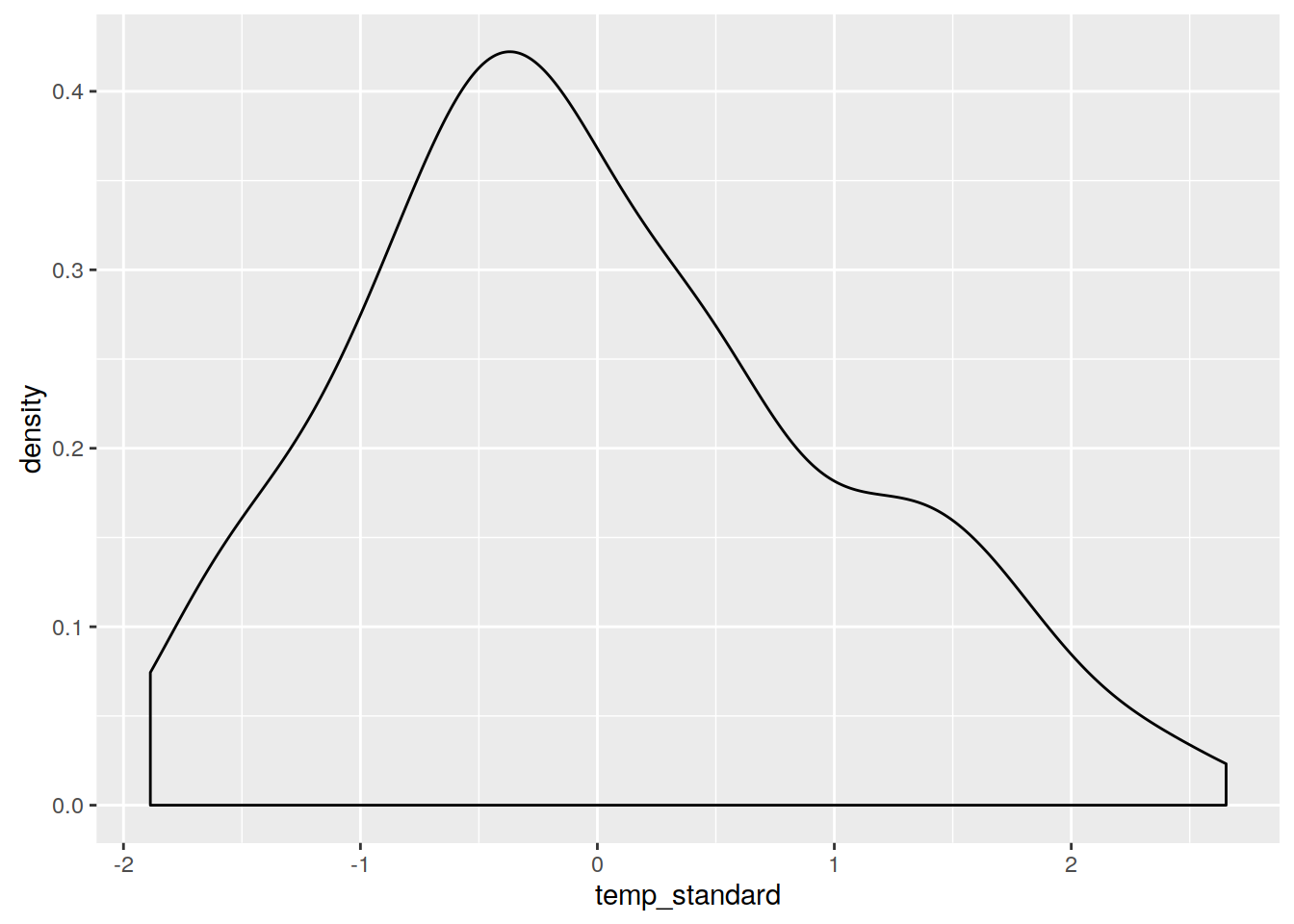
3.6.6 Transformacja danych | Redukcja skośności
Redukcja skośności:
- Logarytmizacja
- Pierwiastkowanie
- Inne
3.6.7 Transformacja danych | Logarytmizacja
Logarytmizacja w R może odbyć się za pomocą funkcji log(). Transformację logarytmiczną można odwrócić używając funkcji exp().
ggplot(punkty@data, aes(temp)) + geom_density()
punkty$log_tpz <- log(punkty$temp)
ggplot(punkty@data, aes(log_tpz)) + geom_density()
punkty$exp_tpz <- exp(punkty$log_tpz)
ggplot(punkty@data, aes(exp_tpz)) + geom_density()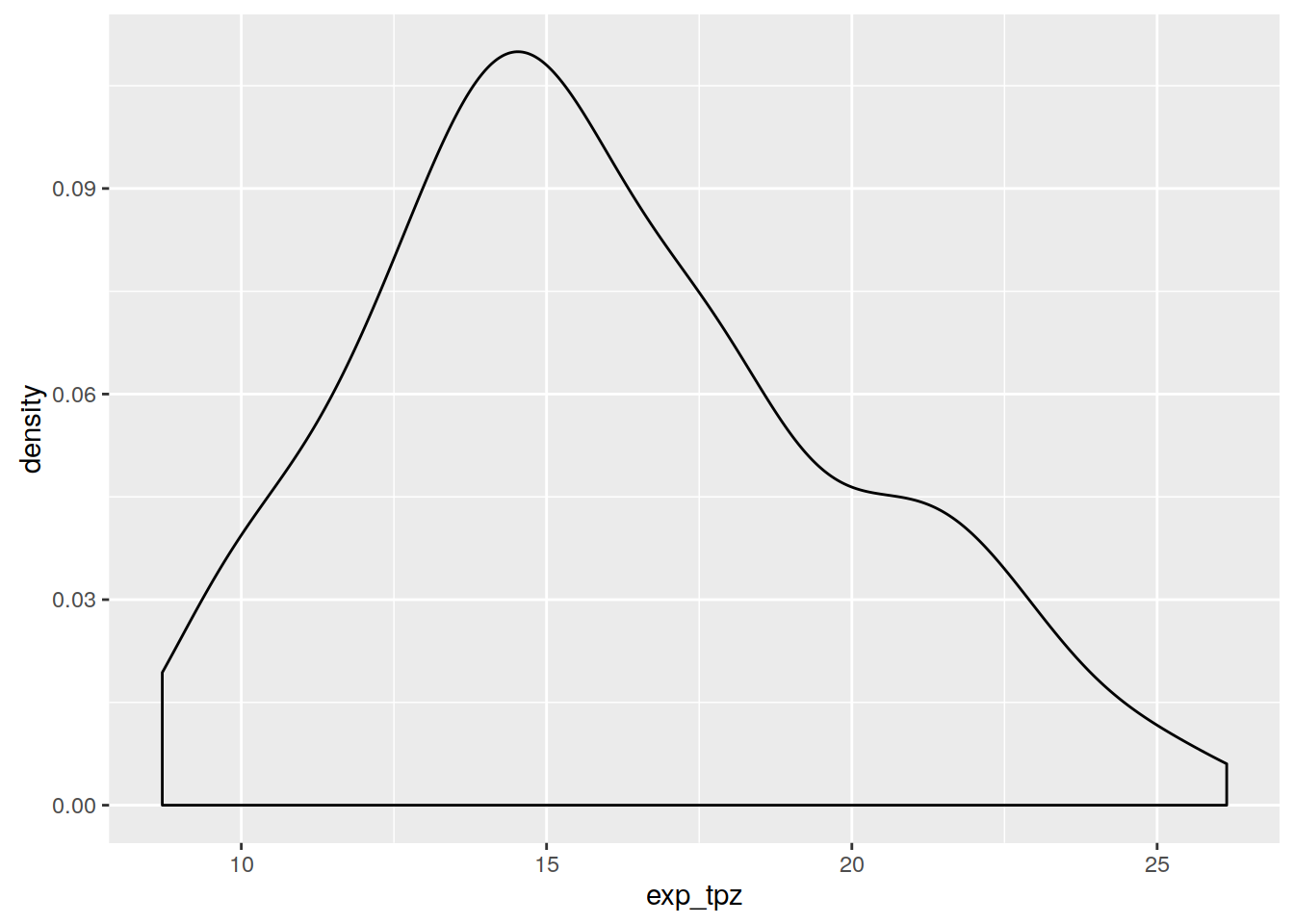
3.6.8 Transformacja danych | Pierwiastkowanie
Pierwiastkowanie w R może odbyć się za pomocą funkcji sqrt(). Odwrócenie tej transformacji odbywa się poprzez podniesienie wartości do potęgi (^2).
ggplot(punkty@data, aes(temp)) + geom_density()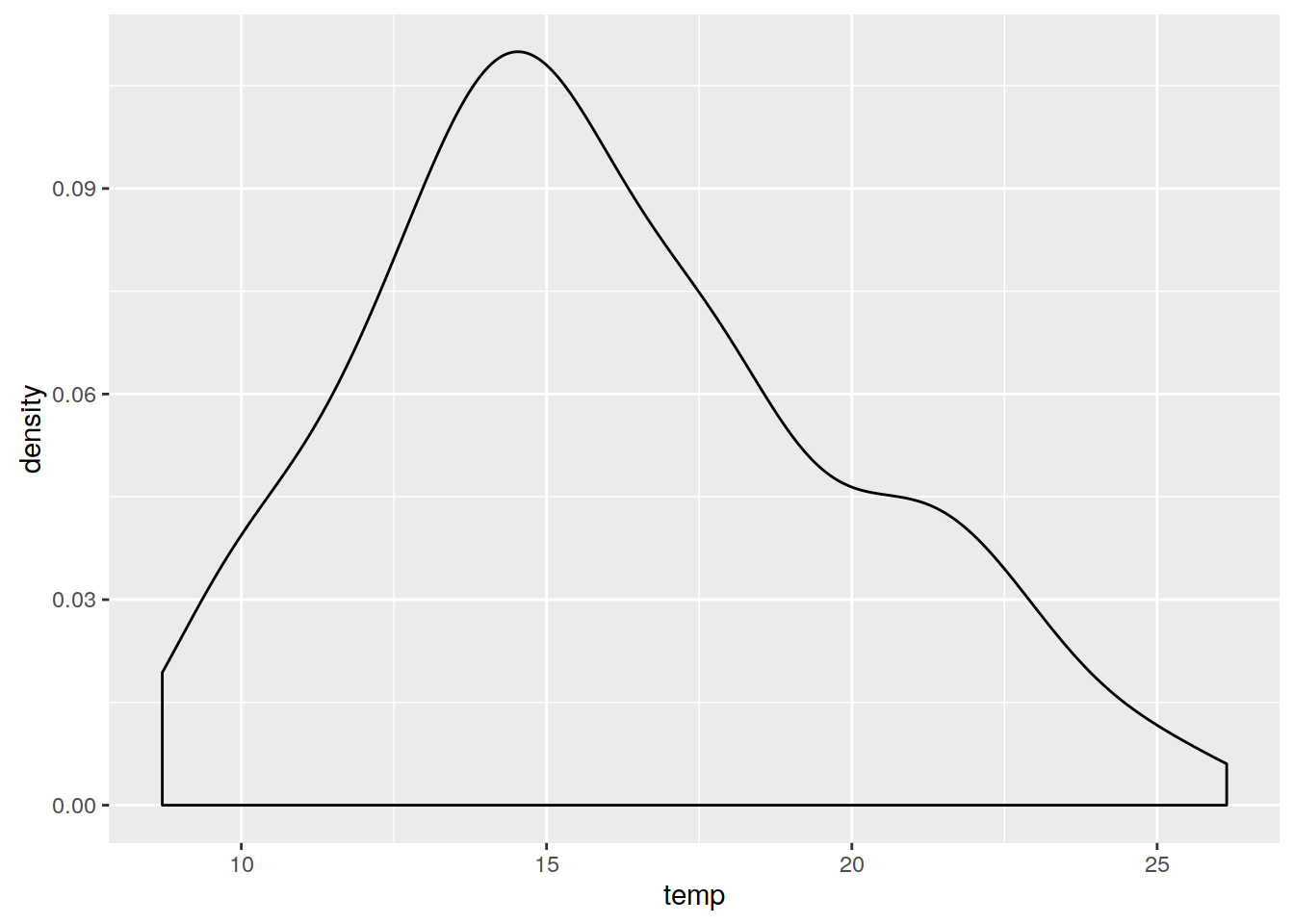
punkty$sqrt_tpz <- sqrt(punkty$temp)
ggplot(punkty@data, aes(sqrt_tpz)) + geom_density()
punkty$pow_tpz <- punkty$sqrt_tpz^2
ggplot(punkty@data, aes(pow_tpz)) + geom_density()