|
|
Warto wiedzieć
Mirosława Mocydlarz
Udostępnianie informacji naukowej na nośnikach elektronicznych
Rozdział 7.
Kompresja i archiwizacja elektronicznych dokumentów tekstowych.
7.1. Kompresja - metody, algorytmy i aplikacje kompresji dokumentów pełnotekstowych.
Pomimo tego, że mamy do dyspozycji wielogigabajtowe dyski twarde, nie możemy zapominać o ich rozsądnym wykorzystaniu. Składujemy na nich duże ilości danych i dlatego warto najrzadziej używane pliki "ścieśnić" aby dużej nie nękał problem zbyt małej pojemności nośników danych.
Termin kompresja danych pojawił się ponad pół wieku temu wraz z rozwojem nowej gałęzi informatyki - teorii informacji. Za twórcę uważa się Claude'a Shannona, który pracował nad komunikacją, informacją i sposobami przesyłania i przechowywania danych. Należy jednak zwrócić uwagę, że prawdziwym prekursorem kompresji i zarazem autorem jej skutecznej implementacji był Samuel Morse, wynalazca telegrafu oraz pierwszego binarnego kodu alfanumerycznego. Sposób, w jaki Morse ułożył swój kod, jest zgodny z teoriami opracowanymi sto lat później przez Shannona i jego następców.
Kompresja danych jest technologią, która pozwala na zmniejszenie ich objętości, bez uszczerbku dla zawartej w nich informacji. Polega, w uproszczeniu, na wyszukaniu w zbiorze danych często powtarzających się znaków lub ciągów znaków i zastąpieniu ich takim zapisem, który zajmuje znacznie mniej miejsca. Wyróżnić można dwa rodzaje kompresji:
- ilościowa (bezstratna);
- jakościowa (stratna).
W przypadku pierwszym wielokrotna kompresja i dekompresja nie powodują utraty żadnej części informacji. Dane są wiernie zakodowywane i rozkodowywane. Zwykle wykorzystuje się w tym celu częstsze występowanie pewnych kodów w całym lub części pliku. Kody te zapisuje się jako ciągi bitowe o długości odwrotnie proporcjonalnej do częstości występowania. Kompresję ilościową można zrealizować dynamicznie (dane w miarę nadchodzenia kolejnych bitów są kompresowane lub dekompresowane) lub statycznie (dane są przeglądane w całości, po czym w całości są kompresowane lub dekompresowane). Kompresja realizowana dynamicznie mimo częstszego stosowania może mieć gorsze parametry od statycznej.
Kompresja jakościowa jest stosowana w popularnych formatach zapisu obrazów lub dźwięków oraz urządzeniach audiowizualnych i powoduje, najczęściej niezauważalną dla naszych zmysłów, utratę szczegółów. W zamian uzyskuje się bardzo wysoki współczynnik kompresji. W dalszej części pracy dotyczącej kompresji nie będę zajmowała się kompresją stratną, gdyż jest ona charakterystyczna dla wyżej wymienionych typów plików, a moja praca dotyczy informacji naukowych - plików tekstowych, w których jakakolwiek utrata danych jest niemożliwa.
Współczynnik kompresji jest miarą stosunku rozmiaru pliku pierwotnego do jego rozmiaru po kompresji. Jeśli plik po kompresji jest dwa razy mniejszy od pierwotnego to oznacza to, że współczynnik kompresji wynosi 2:1. Inaczej: miejsce potrzebne na jednostkę danych na dysku pomieści po kompresji dwie jednostki danych. Większy współczynnik (np. 3:1) oznacza silniejszą kompresję, a mniejszy (np. 1,5:1) słabszą. Dla różnych typów plików istnieją różne współczynniki kompresji:
- pliki tekstowe - pliki tworzone przez edytory (pliki tekstowe, dokumenty) zwykle kompresują się dobrze. Współczynniki kompresji często osiągają 3:1 lub 4:1;
- pliki baz danych - pliki tworzone przez programy, np. Access firmy Microsoft, FileMaker for Windows, dBase i podobne, mają zwykle wysoki współczynnik kompresji, który jednak zależy od typu zmagazynowanych w nich danych (liczby, tekst, grafika, dźwięki) oraz od struktury pliku. Należy jednak spodziewać się współczynników od około 2:1 do 3,5:1 lub wyższych.
- Pliki graficzne - do najlepiej kompresujących się plików graficznych należą pliki grafiki bitowej (BMP, PCX). Pliki GIF oraz niektóre odmiany plików TIFF należą do tej grupy, która nie kompresuje się dobrze. Kompresja jednak plików graficznych nie jest tematem mojej pracy.
7.1.1. Algorytmy kompresji bezstratnej.
Metody kompresji bezstratnej można podzielić na:
- probabilistyczne;
- słownikowe.
Metody probabilistyczne bazują na rozkładzie prawdopodobieństwa występowania poszczególnych znaków w zbiorze i generowaniu odpowiedniego skończonego ciągu symboli, na bazie tego rozkładu. Ciąg symboli składa się różnej długości kodów, które mogą być budowane jedną z metod: statyczną (przejrzenie całego zbioru danych przed kodowaniem i ułożenie odpowiedniego alfabetu, który przekazany dekompresorowi, musi być dodatkowo zapisany w kompresowanym pliku) lub adaptacyjną (nie ma potrzeby przeglądania pliku, ani przekazania alfabetu do dekompresora);
Metody słownikowe polegają na zastępowaniu powtarzających się bloków danych wskaźnikami do miejsca ich pierwszego wystąpienia. Opiera się na strukturze (słowniku), który jest zbiorem pewnych fraz (wyrazów) występujących w tekście źródłowym. Kodowanie polega na pobieraniu symboli ze strumienia wejściowego, grupowaniu ich we frazy i sprawdzaniu, czy dana fraza znajduje się już w słowniku. Jeżeli zostanie znaleziona, eliminuje się jej indeks (adres, wskaźnik), opisujący pozycję danej frazy w słowniku, a jeżeli nie, to dodaje frazę do słownika. Do najczęściej spotykanych algorytmów probabilistycznych zaliczamy: metodę Huffmana i Shannon-Fano.
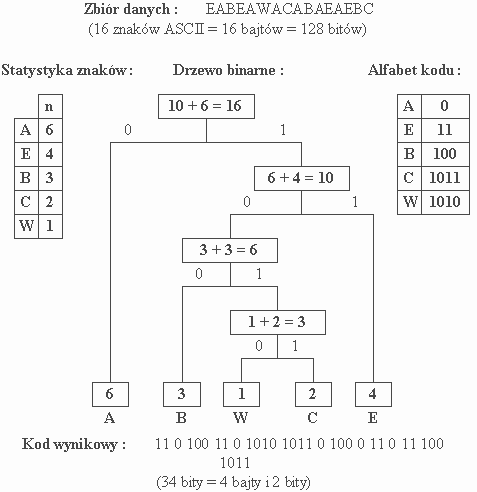
Statystyczne kodowanie Huffmana jest najczęściej stosowanym algorytmem probabilistycznym w programach kompresujących. Jej celem jest ułożenie kodu o zmiennej długości słowa, dopasowanego do zawartości zbioru danych. Procedura rozpoczyna się od zebrania statystyki wystąpień poszczególnych bajtów w całym zbiorze. Drugi etap polega na zbudowaniu drzewa binarnego, w którego koronie jako liście umieszcza się znaki wg zasady: występujące najczęściej - na zewnątrz grafu, najrzadziej - w jego środku (Rysunek 6.). Drzewo tworzy się, łącząc kolejno w pary elementy o najmniejszej liczbie powtórzeń. Wygenerowanie nowego kodu dla wybranego znaku następuje w wyniku przejścia drogi od wierzchołka drzewa do odpowiedniego liścia, przy czym każdy krok w lewą stronę powoduje dodanie do słowa kodowego zera, krok w prawo - jedynki. Powstający w ten sposób unikatowy alfabet kodu musi być dołączony do kompresowanego zbioru.
Rysunek 7. Przykład kodowania metodą Huffmana.
Metoda Shanon-Fano działa na podobnej zasadzie, co metoda Huffmana. Różnica polega na innym, mniej efektywnym sposobie budowania drzewa binarnego - od wierzchołka do liści. W związku z tym, iż działanie takiego algorytmu doprowadza do powstania takiego samego drzewa jak w metodzie Huffmana, takiego kodowania praktycznie nie stosuje się. Kodowanie statyczne ma następujące wady: odkodowanie wymaga przesłania do pliku wyjściowego informacji, jak wygląda drzewo, co w przypadku małych plików (kilkadziesiąt bajtów) jest nieopłacalne bowiem już samo zapisanie informacji potrzebnej do dekompresji spowoduje zwiększenie pliku o co najmniej kilkaset bajtów; rozpoczęcie kodowania wymaga przejrzenia całego zbioru danych w celu zbudowania prawdopodobieństwa występowania poszczególnych znaków, co w przypadku dość dużego pliku zajmuje sporo czasu.
Rozwiązaniem problemów statycznych metod kodowania jest kodowanie adaptacyjne. Polega na wykorzystaniu modelu statystycznego, w którym znane są tylko dwa symbole: EOS
118 - znacznik końca strumienia bitowego i ESC
119 - znacznik wystąpienia nowego znaku. ESC przekazuje informację programowi dekompresującemu o tym, że następny znak nie będzie zakodowany według budowanego modelu, ale jako informacja o stałym rozmiarze. Model statystyczny wykorzystywany do kodowania jest modyfikowany po nadejściu każdego symbolu. Dzięki temu można pełniej oddać charakterystykę źródła i dostosować się do jej lokalnych zmian. Wśród metod słownikowych kompresji na uwagę zasługuje rodzina odmian algorytmu zaproponowanego w 1977 roku przez Abrahama Lempela i Jacoba Ziva - algorytm Lempel-Ziv (LZ). Różnice między kolejnymi odmianami polegają na zastosowaniu odmiennych struktur danych do konstruowania słownika, począwszy od liniowej tablicy, na drzewach wielogałęziowych skończywszy. Zasada działania algorytmu LZ jest następująca: w oryginalnym pliku wyszukuje się powtarzające się sekwencje bajtów. Przykładowo w zdaniu "Pije Kuba do Jakuba" powtarzającą się sekwencją jest sekwencja liter "uba". Każde następne pojawienie się tego ciągu liter jest zastępowane przez algorytm jednoznakowym wcześniej zdefiniowanym symbolem. Sama sekwencja zapisana jest tylko raz. W procesie dekompresji symbole umieszczone w pliku zastępowane są kopiami sekwencji reprezentowanych przez dany symbol. Ponieważ skompresowane dane mogą być odtworzone wiernie algorytm LZ określany jest jako algorytm bezstratny.
7.1.2. Kompresja plików tekstowych.
W kompresji chodzi przede wszystkim o zmniejszenie objętości danych. Ważna jest jednak przy tym jej skuteczność i czas, jaki zajmuje. Istnieje wiele pakerów dokumentów tekstowych, niektóre zostały omówione powyżej, do prostych i interesujących można zaliczyć następujący sposób pakowania tekstów.
Każdy znak w tekście to 1 bajt (8 bitów). Tablica znaków ASCII zawiera 256 różnych znaków. Można powiedzieć, że nic nie da się tu skompresować ale gdy policzymy liczbę znaków w alfabecie, które używamy pisząc tekst (małe i duże litery, kilka znaków specjalnych - cyfry przestankowe, matematyczne) to maksymalnie w użytku jest 110, może 120 znaków. A pozostałe około 136 znaków nigdy praktycznie nie używamy. Jeżeli jeszcze przyjrzymy się wyrazom w tekście, to dojdziemy do wniosku, że dwu- i trzyliterowe zlepki, np. "nie", "dz", "się", "czy", itd. często się powtarzają i zajmują po 2, 3 bajty i dlatego można je oznaczyć jakimś jednym znakiem, to zajmować będą tylko jeden bajt.
Każda litera to jeden bajt, możemy więc mieć 256 różnych wartości. Tworzymy więc tablicę 256-elemetnową składającą się z ciągów literowych - stringów o maksymalnej długości trzech liter. Tablicę wypełniamy wszystkimi tymi znakami, które w tekście będą występowały na pewno. Pozostałe 136 będą dobrane później. Po wypełnieniu tablicy należy odszukać dwu- i trzyliterowe zbitki, które występują najczęściej. W skutek tego powstaną w tablicy puste miejsca. W ten sposób tablica jest gotowa, i mimo iż posiada wiele luk, które warto zapełnić - co powinno jeszcze zwiększyć stopień kompresji. Jak przebiega kompresja? Na początek z tablicy wczytywana jest linia tekstu, a do zmiennej roboczej (string) dać należy pierwsze trzy litery i sprawdzić, czy takiej zbitki nie ma w tablicy. Jeśli tak to do stringu wynikowego jest zapisywany pierwszy bajt (indeks tablicy dla danej zlepki); jeśli nie należy odciąć ze zmiennej roboczej ostatnią literę i ponownie sprawdzać wśród dwuliterowych zbitek. Procedura postępowania jest identyczna jak powyżej. Jeżeli nie znaleziono takiego elementu obcinana jest ostatnia litera ze zmiennej roboczej i należy szukać jej w tablicy. Jeżeli nie znajduje się tam, wówczas należy poinformować o błędzie. Powyższe kroki należy powtarzać do końca danej linii tekstu i końca pliku. W drugiej zmiennej roboczej należy natomiast zapisywać numer ostatniej litery już spakowanej, aby móc przesuwać się dalej w danej linii. Kiedy cały plik jest spakowany program może go zdekompresować, tj. wczytać stringi skompresowane, zamienić je po kolei według tablicy (tej co użyta była do pakowania) na właściwe litery i zbitki oraz zapis.
Podsumowując warto zwrócić uwagę na wady powyższej metody. Mimo, że jest metodą szybką to jednak nie daje oszałamiających rezultatów a stosować ja się opłaca wtedy, gdy należy kompresować plik o wielkości do kilka kilobajtów, gdyż sama tablica zajmuje 768 bajtów, a więc dla jednej lub kilku linii tekstu to nie ma sensu.
7.1.3. Programy kompresujące.
Programy kompresujące wczytują dane o dużej objętości i mają je zapisać na dysku w postaci pliku o możliwie małej objętości stosując odpowiednie metody kompresji. Dzisiejsze programy łączą zazwyczaj obie metody (słownikową i probabilistyczną), wykonując jako pierwszą kompresję słownikową. Programy dokonujące kompresji można podzielić na:
programy archiwizujące (typu PKZip czy ARJ) - dokonują kompresji plików danych lub programów i następnie zapisują je po przetworzeniu w jednym pliku o specjalnym formacie, którego odtworzenie wymaga ponownego uruchomienia programu archiwizującego (patrz Rozdział 7.2.2.);
programy kompresji aktywnej (typu LZEXE czy PKLITE) - poddają kompresji pliki jedynie z zapisanymi programami (*.exe lub *.com), lecz w taki sposób, że mimo zmniejszenia objętości nadają się one nadal do dalszego wykorzystywania bez konieczności uprzedniej dekompresji specjalnymi programami. Jest to możliwe, dzięki temu, że w tak spreparowanym pliku wykonywalnym znajduje się procedura automatycznie dokonująca dekompresji do pamięci operacyjnej podczas uruchamiania skompresowanego pliku;
programy kompresji na bieżąco (on line), które dokonują kompresji wszystkich danych znajdujących się na dysku twardym lub dyskietce i zapisują je do jednego pliku. Dane tak spreparowane są udostępnione poprzez specjalny rezydujący w pamięci program obsługi, który automatycznie kompresuje lub dekompresuje dane przy próbie odczytu bądź zapisu na dysk. Przykładami takich programów są: Stacker amerykańskiej firmy Stac Electronics i SuperStor.
7.2. Archiwizowanie - wybór oprogramowania i sprzętu do magazynowania pełnych tekstów informacji naukowej.
Cisza przed burzą - tak określana jest sytuację, gdy PC-et pracuje bez komplikacji. Wtedy prawie żaden użytkownik nie myśli o bezpieczeństwie danych i o archiwizacji, bo jak zapewniają producenci, komputer może działać bezproblemowo latami a twardy dysk będzie się kręcić prawie wiecznie. Gdy jednak nagle odtworzenie owoców długotrwałej pracy na komputerze staje się kłopotliwe z powodu awarii systemu czy błędu sprzętu, na tworzenie kopii bezpieczeństwa jest już za późno a odtworzenie utraconych informacji staje się zwykle niemożliwe. Nieodwracalna utrata informacji jest problemem nie tylko użytkowników ale przede wszystkim administratorów sieci lokalnych, dla których dostęp do aktualizowanych na bieżąco, jak i archiwalnych zbiorów jest istotą funkcjonowania systemu komputerowego. Uszkodzenie natomiast jedynego serwera, używanego do przechowywania i obsługi ważnych danych w bibliotece naukowej może doprowadzić do nieprzewidzianych następstw, policzalnych w kategoriach finansowych. Dlatego żadna licząca się i skomputeryzowana biblioteka nie pozwoli sobie na lekkomyślność i nie trzeba jej będzie przekonywać do zabezpieczenia własnych zbiorów. Znalezienie jednak odpowiedniego rozwiązania nie przychodzi łatwo trzeba uwzględnić wszystkie możliwe awarie komputerów, serwerów i pamięci dyskowych a także włamania, pożary, uderzenia piorunów, itp. Natomiast dostępnych urządzeń do backupu danych: różnorodnych nośników pamięci, napędów do przechowywania danych w postaci kopii bezpieczeństwa (kasety, streamery), urządzeń ochrony (stabilizatory, zasilacze bezawaryjne UPS) i przede wszystkim właściwego oprogramowania dla bibliotek (Autoloader, Jukebox), niezbędnego do składowania i utrzymywania procesu bezpiecznej archiwizacji z możliwością wyszukiwania danych jest wiele.
7.2.1. Strategie tworzenia kopii bezpieczeństwa i metody archiwizacji.
W procesie składowania i ochrony informacji rozróżnia się dwa zbliżone pojęciowo określenia: archiwizacja i tworzenie kopii bezpieczeństwa (backup). Kopie bezpieczeństwa, których nie należy mylić z kopiami archiwalnymi, są wykonywane w celu zabezpieczenia bieżących i aktualnych danych przed przypadkowym zniszczeniem. Jest to więc wierna kopia informacji z roboczej pamięci masowej systemu, tworzona w sposób prawie ciągły na wypadek awarii prze określony czas, co umożliwia odtworzenie stanu informacji z okresu poprzedzającego wystąpienie uszkodzenia.
Przy wyborze strategii tworzenia backupu należy uwzględnić szereg parametrów: potrzeby biblioteki z kosztem instalacji systemu, ciężar gatunkowy rejestrowanych modyfikacji, ich częstość i maksymalny czas składowania. Dla tak przyjętych założeń można dopiero określać wersje tworzenia kopii bezpieczeństwa. Stosowanie tzw. "nocnych zrzutów" informacji dyskowej na trwalsze pamięci masowe (nośniki taśmowe), ze względu na długie czasy dostępu do medium, nie zawsze spełniają efektywnie swoją rolę. Poza tym dane zgromadzone lub przetworzone między kolejnym dobowym składowaniem mogą okazać się zbyt duże i stanowić znaczącą część całości chronionej informacji. Z kolei wykonanie pełnej archiwizacji - kopii wszystkich plików systemu, nie jest rozsądne, gdyż wymaga dużo czasu i zużywa urządzenia do wykonywania kopii zapasowych w większym stopniu niż inne rodzaje archiwizacji: przyrostowej czy różnicowej (tabela 4).
Tabela 4. Procedury składowania.
|
Backup pełny (full) |
Różnicowy backup tygodniowy (differential) |
Backup przyrostowy (incremental) |
- archiwizacji podlegają wszystkie dane niezależnie od tego, kiedy były archiwizowane po raz ostatni;
- wszystkie dane znajdują się na jednej taśmie (ewentualnie komplecie taśm);
- najkrótszy czas potrzebny na odtworzenie danych;
- najdłuższy czas potrzebny na archiwizację.
|
archiwizacji podlegają wszystkie dane, które zostały zmodyfikowane po ostatniej pełnej archiwizacji;
stosunkowo szybka metoda archiwizacji;
ilość danych oraz czas archiwizacji wzrastają w skali tygodnia;
potrzebna jest większa liczba kaset niż w przypadku archiwizacji pełnej. |
archiwizacji podlegają tylko nowe pliki I pliki modyfikowane po ostatniej archiwizacji;
najszybsza metoda archiwizacji (nie wliczając czasu wykonania jednego backupu pełnego w skali tygodnia);
potrzebna jest większa liczba kaset;
czas odtwarzania danych jest najdłuższy z omówionych strategii.
|
Powszechnie stosowanym rozwiązaniem jest tworzenie trójpokoleniowej rotacji taśm magnetycznych, oddzielnie dla każdego tygodnia, co przez okres trzech tygodni daje 21 nośników kopii zapasowych. W ciągu tego okresu, zwanego oknem kopii zapasowej, istnieje więc kopia danych sieciowych odzwierciedlająca stan do trzech tygodni wstecz. Po upływie tego okresu najstarsze zapisy są niszczone poprzez nadpisywanie. Właściwym jednak rozwiązaniem jest ciągłe i automatyczne gromadzenie i zabezpieczanie danych na wolniejszych i pojemniejszych nośnikach niż pamięć podstawowa (zwykle główna pamięć dyskowa systemu). Zaktualizowane zapasowe kopie przetwarzanych informacji znajdują się w bezpiecznym miejscu biblioteki
120 , a przyłączenie takiej pamięci zewnętrznej do sieci lub systemu umożliwia prawie natychmiastowe odtworzenie zgromadzonych danych. Archiwizacja danych jest sposobem tworzenia kopii zapasowych polegającym na przenoszeniu plików (migracji) na zewnętrzne nośniki informacji o dużej pojemności: taśma magnetyczna, dysk optyczny lub magnetooptyczny, ale archiwowany plik jest usuwany z serwera dyskowego w celu odzyskania miejsca do tej pory zajmowanego przez ten zbiór. Taśmy archiwalne nie mogą jednak być powrotnie używane do zapisu, uaktualniane, modyfikowane. Zindeksowane tematycznie i chronologicznie z informacją, ajkie zawierają pliki i katalogi przekazywane są do archiwum, z którego nawet po wielu latach można korzystać w systemie off-line, jak i on-line. Po upływie zdefiniowanego okresu archiwizacji ulegają natomiast zniszczeniu. Zapis danych do archiwum może być realizowany przy użyciu różnego rodzaju urządzeń. Wybór najodpowiedniejszego zależy min. od: rozmiarów zapisywanych zasobów, kosztów napędu, szybkości działania, czasu dostępu do informacji oraz maksymalnego przewidywanego czasu przechowywania nośnika archiwalnego. Kopie archiwalne dokumentują zamkniętą część działalności biblioteki, zarówno dokumenty tekstowe, jak i zeskanowane dokumenty czy obrazy. Powinny więc być przechowywane i dostępne na życzenie poza pomieszczeniami bibliotek
121 , ale korzystanie z nich przez zwykłych użytkowników systemów komputerowych powinno być ograniczone a nawet niemożliwe. Istnieje wiele sposobów sporządzania kopii, do najpopularniejszych należą: - kopiowanie okresowe w regularnych odstępach czasu, np. co kilka minut;
- kopiowanie ciągłe, które utrzymuje w aktualności zarówno kopię podstawową, jak i kopie wszystkich plików podlegających modyfikacji. Możliwe jest odtworzenie stanu plików w dowolnej chwili sprzed lub po modyfikacji;
- system mirroring, w którym wszelkie modyfikacje plików zapisuje się równolegle i równocześnie na dwu pamięciach dyskowych. System musi mieć zainstalowane co najmniej dwa napędy dysków twardych, a w przypadku awarii jednego z nich drugi nadal obsługuje bieżących użytkowników;
- system duplexing, w którym ochroną są objęte również sterowniki dyskowe.
Obecnie można rozróżnić cztery metody archiwizacji stosowane w polskich bibliotekach (Tabela 5):
Tabela 5. Metody archiwizacji stosowane w polskich bibliotekach.
|
Metody |
Tradycyjny |
Mikrofilmowy |
Elektroniczny |
Hybrydowy |
|
Działanie |
przechowywanie, udostępnianie oryginału;
|
fotografowanie dokumentów na mikrofilmach zwojowych 16 i 35 mm szerokich oraz mikrofiszach formatu A6;
|
skanowanie dokumentów i przechowywanie na dysku optycznym, magnetooptycznym czy CD-ROM-ie;
|
łączy system mikrofilmowy z elektronicznym; |
|
Zalety |
możliwość korzystania z oryginału;
|
duża trwałość błony mikrofilmowej (100-500 lat);
wysoka rozdzielczość sięgająca 1200 dpi;
kompatybilność z wszystkimi najnowszymi systemami i urządzeniami;
normy międzynarodowe precyzujące system;
|
szybki dostęp do dużej liczby dokumentów;
minimalna ilość miejsca potrzebna do założenia archiwum;
|
najpewniejszy system;
gwarantuje użytkownikowi szybki dostęp do dokumentu - informacji;
możliwość trwałego zabezpieczenia;
|
|
Wady |
duże koszty przechowywania zbiorów;
problemy z odszukaniem;
|
duży koszt zakupu urządzeń;
dłuższy niż w systemie elektronicznym czas wyszukiwania dokumentu;
długi proces technologii;
|
brak form regulujących system;
brak standaryzacji formatu zapisu;
szybki czas starzenia się sprzętu komputerowego
|
|
7.2.2. Programy do archiwizacji.
Programy archiwizujące zwane żargonowo archiwizatorami, pakerami należą do grupy programów narzędziowych przeznaczonych do umieszczania plików w archiwach danych i odtwarzania zapisanych w nich danych. Oprogramowanie umożliwiające archiwizację danych ma wszelkie cechy oprogramowania backupu oraz dodatkowo pozwala na rejestrację i kontrolę czasu przechowywania zbiorów archiwalnych. Archiwizacja zwykle połączona z kompresją danych w celu uzyskania maksymalnie zagęszczonej formy informacji, jest powszechnie stosowana. Do najpopularniejszych zastosowań archiwizatorów należą:
- kompresja plików na dyskietkach - do tworzenia kopii własnych danych po zakończeniu pracy np. nad projektem;
- kompresja dużych porcji informacji w pamięci dyskowej. Dla tego typu zastosowań używane są dwa typy archiwizatorów: kompresujące wyniki po dokonaniu całości zadania i dokonujące kompresji "w locie", ale znacznie spowalniające pracę komputera;
- przenoszenie większych plików danych między komputerami za pomocą transmisji. Oszczędności uzyskiwane przy przesyłaniu skompresowanych programów i danych na odległość są wprost proporcjonalne do stopnia kompresji danych i bezpośrednio policzalne.
Oprócz zalet programy do archiwizacji danych mają także wady: zwiększenie czasu pracy z plikami spakowanymi i wrażliwości na uszkodzenia tych plików. Odzyskanie poprawnej informacji z pliku spakowanego, który uległ uszkodzeniu jest na ogół kłopotliwe, a wręcz niemożliwe. Metody kontroli błędów jedynie sygnalizują błąd, identyfikują lub usuwają uszkodzone pliki podczas rozpakowywania informacji.
Do najbardziej znanego oprogramowania należą archiwizatory, które odznaczają się wysokimi współczynnikami kompresji plików tekstowych: PKZip, ARJ, LHA, RAR czy BOA Constrictor Archiver. Istnieje jednak i wiele innych, np. GZIP, PKPak, LHArc, itp. Najnowsze wersje popularnych archiwizatorów mają podobne funkcje i różnią się tylko szczegółami ukazującymi się dopiero w różnych sposobach ich wykorzystywania jako: kompresja szybka (najkrótszy czas, najniższy współczynnik kompresji), kompresja dokładna (najwyższa kompresja, najdłuższy czas) i kompresja standardowa stanowiąca optymalny kompromis między szybkością przetwarzania a zyskiem kompresji.
PKZip, produkt amerykańskiej firmy PKWare jest jednym z najbardziej popularnych programów archiwizujących zawierający oddzielne programy do kompresji, dekompresji, generowania samorozpakowujących się archiwów i korekcji uszkodzonych fragmentów archiwum. Pozwala również tworzyć archiwum znajdujące się na wielu dyskietkach.
Program archiwizujący ARJ, opracowany przez Roberta K. Junga, spełnia podobne funkcje jak powyższy przy zbliżonym współczynniku kompresji i niewiele wolniej działającej kompresji danych. Ponadto umożliwia konwersję plików generowanych przez inne archiwizery (PKZip, LHA) do postaci ARJ, archiwizację kilku wersji tego samego pliku, wyszukiwanie ciągu znaków w archiwach, łatwe przenoszenie (110 kB) archiwizatora do innych systemów.
Stworzony przez Japończyka archiwizator LHA o objętości 32 kB uzyskał do niedawna najwyższe współczynniki kompresji kosztem jednak czasu jej wykonywania. Wersja programu ustępuje powyżej opisanym, zarówno pod względem współczynników kompresji jak i czasów jej realizacji. Najbardziej dotkliwym brakiem jest brak możliwości tworzenia archiwów wielosegmentowych i brak możliwości zabezpieczania plików hasłem oraz brak narzędzia pozwalającego na rekonstrukcję uszkodzonych archiwów.
Archiwizator RAR, który opracował Rosjanin J. Roshal, wyposażony jest w aktywny interfejs użytkownika a w testach szybkości pakowania danych ustępuje tylko programom PKZip. Oprócz podstawowych funkcji (tworzenie, obsługa i rekonstrukcja archiwów, tworzenie plików SFX) RAR posiada funkcję tworzenia archiwów wielosegmentowych, możliwość przeglądania zawartości plików spakowanych a także możliwość "sklejania" plików przed rozpoczęciem archiwizacji (tzw. archiwa blokowe) dzięki czemu osiąga mniejsze rozmiary zbiorów w porównaniu do zbiorów wykonanych przez inne archiwizery.
BOA Constructor Archiver to prostszy archiwizator od omówionych powyżej. Rożni się od nich przede wszystkim brakiem niektórych opcji, jak np. rozbudowanych systemów pomocy. Program ten jednak w teście programów do archiwizacji i kompresji danych znalazł się w ścisłej czołówce jako bardzo skuteczny archiwizer tekstu oraz dźwięku.
Osiągi opisanych programów są bardzo podobne. Poniżej zestawiono czasy i współczynniki kompresji dla kilku plików pakowanych różnymi metodami za pomocą programów PKZip, ARJ, RAR, LHA. Kompresji poddano pliki: HTML, Office oraz PDF. Najbardziej zadawalający współczynnik kompresji dla plików tekstowych oraz plików wyświetlania tekstów na stronie WWW osiągnął program RAR. Podobnie było z czasem potrzebnym na kompresję danych plików.
Tabela 6. Wyniki testów programów kompresujących.
|
|
ARJ |
LHA |
PKZip |
RAR |
|
Algorytm kompresji |
algorytm Huffmana |
algorytm Huffmana |
algorytm Storera Imploding |
algorytm kompresji i dekompresji RAR |
|
Kompresja: uzyskana [%] |
|
|
|
|
| |
rozmiar plików [kB] |
liczba plików |
|
|
|
|
|
HTML |
8070 |
763 |
68,63 |
brak danych |
67,85 |
79,43 |
|
Office |
1723 |
31 |
76,09 |
brak danych |
76,37 |
84,55 |
|
PDF |
2054 |
3 |
35,04 |
brak danych |
34,87 |
54,91 |
7.2.3. Sprzęt.
W nowoczesnych systemach informatycznych pojemność pamięci dyskowych podwaja się przeciętnie co półtora roku i chociaż tak samo jest z mocą obliczeniową systemów komputerowych i serwerów, to liczba danych przeznaczonych do ochrony i archiwizowania jest tak duża, że na ich właściwe zabezpieczenia zaczyna brakować mocy i czasu. Dodatkowo na rynku pamięci masowych (urządzeń do archiwizacji i tworzenia kopii bezpieczeństwa) pojawia się problem niezgodności standardów i urządzeń. Popularność jednak zdobyła niewielka liczba technologii mimo, iż miniaturyzacja i nowe technologie spowodowały zmiany jakościowe we wszystkich rodzajach napędów stosowanych w pamięciach wewnętrznych i zewnętrznych: dyskietki, dyski stałe i wymienne, CD-ROM-y, taśmy magnetyczne (napędy kasetowe, streamery), dyski optyczne i magnetooptyczne. Nowe nośniki i nowe napędy zaczynają oferować dostęp do znacznie większych niż do tej pory stosowanych pojemności.
Konwencjonalne napędy dyskietek elastycznych 2HD użytkowane od kilkunastu lat jako pamięci wymienne w komputerach klasy PC, oferują maksymalną pojemność 1,44 MB. Kontroler napędu takiej dyskietki pozwala na przesyłanie danych z prędkością 500 Mb/s (62,5 kB/s) ale praktycznie informacja jest zapisywana z szybkością nie większą niż 30 kB/s przy maksymalnej prędkości obrotowej 300 obr./min. Dyskietka jednak przy obecnych pojemnościach dysków twardych i ilości przetwarzanych danych, nie jest praktycznie żadną ochroną. Mała pojemność, duża zawodność nośnika i wysoka cena dyskwalifikują dyskietkę jako nośnik do archiwizacji.
Macierze dyskowe RAID są stosowane ze sprzętem bardzo wysokiej jakości. Ich cena jednak wzrasta proporcjonalnie do pojemności - przy większych pojemnościach są bowiem bardzo drogie. Pamięci półprzewodnikowe używane w tych systemach, jako pamięć podręczna, cechuje duża prędkość ale i wysoka cena.
Napędy taśmowe nadal doskonale nadają się do archiwizacji i przechowywania danych, i mimo, iż twarde dyski stają się coraz bardziej niezawodne nadal zdarzają się awarie, a jak mówi jedno z praw Murphie'ego prawdopodobieństwo ich wystąpienia rośnie proporcjonalnie do ważności informacji.
Pamięci taśmowe z nośnikiem w kasecie (streamery) były pierwszymi urządzeniami do sporządzania kopii zapasowych z dysków stałych. Do tej pory należą do najtańszych metod zapisu dużej ilości danych. Techniki zapisu na tych nośnikach można klasyfikować według rodzaju używanych kaset: kasety z taśmą półcalową lub ćwierćcalową (technologia QIC
122 , Travan - najtańsze, średni czas dostępu jest dłuższy aniżeli dla konkurencyjnej technologii DAT), kasety DAT 4 (4 mm, opracowane pierwotnie do zapisu dźwięku - wysoka cena, wysoki stopień upakowania danych) i DAT
123 8 (8 mm, przetwarzanie i archiwizacja). Dla mniejszych bibliotek zalecane jest stosowanie kaset z taśmą QIC lub Travan, do obsługi sieci większych bibliotek kasety z taśmą 8 mm (technologia DLT
124). Technologia DAT 4 została adoptowana zwłaszcza do składowania i archiwizacji danych, zwłaszcza w serwerach z obsługą niewielkich sieci LAN.
Tabela 7. Porównanie parametrów najważniejszych technologii zapisu danych.
|
Rodzaj nośnika |
Zapis |
Pojemność GB (bez kompresji) |
Przepustowość (MB / s) |
Średni czas dostępu |
Żywotność głowicy (h) |
Żywotność taśmy (liczba przewinień) |
|
QIC (1/4") |
liniowy
125 | 0,06 - 1,35 | 0,60 |
35 s |
|
|
|
DAT 8 Exabyte |
ukośny
126 | 7 | 0,50 - 1,00 |
minuty |
2 000 |
1 500 |
|
DAT 8 Mammoth |
ukośny |
20 |
3,0 |
20 s |
35 000 |
20 000 |
|
Travan |
liniowy |
0,4 - 4 |
0,56 - 0,62 |
|
|
|
|
DAT 4 |
ukośny |
1 - 4 |
0,54 |
25 s |
2 000 |
5 000 |
|
DLT |
liniowy |
35 |
5,00 |
45 s |
30 000 |
1 000 000 |
Napędy ZIP firmy Iomega są jednymi z najpopularniejszych nośników wymiennych. Dotychczasowa pojemność wzrosła ze 100 MB do 250 MB jednak szybkość napędów nie jest zachwycająca (ok. 0,3-1 MB/s). Napędy ZIP (250 MB) potrafią obsługiwać dyski o pojemności 100 MB, jednak operacje zapisu i odczytu na takich nośnikach przebiegają ok. dwukrotnie wolniej w porównaniu do napędów przystosowanych do mniejszej pojemności.
Napędy ZIP są doskonałym narzędziem do archiwizacji plików - zabezpieczenia tylko wybranych plików i katalogów znajdujących się na dysku twardym. W przypadku wykonywania backupu całego dysku potrzeba dość pokaźnej liczby nośników co sprawia, że samo działanie archiwizacji staje się uciążliwe.
Napędy SyJet mają podobne właściwości co napędy ZIP a ich cechy stawiają je między technologią dysków elastycznych i dysków twardych. Napęd dysku jest na stałe instalowany w komputerze, wymianie ulega jedynie nośnik zamknięty w specjalnej kasecie. Po jej włożeniu do napędu pamięć zachowuje się jak dysk trwały o porównywalnych czasach dostępu i pojemności do 270 MB w wersji standardowej do 1,5 GB. SyJet jest najlepszym wyborem dla bibliotek, w których istnieje potrzeba pojemności i szybkości porównywalnej z dyskiem twardym.
Napędy JAZ to napędy stosowane w kolejnej wersji dysków wymiennych o standardowej pojemności 1 GB do 2GB oparte na układzie głowic magnetycznych. Średni czas dostępu do danych umieszczonych w pamięci z napędem JAZ wynosi 12 ms, a szybkość przekazu około 5,5 MB/s. Wewnątrz kasety znajdują się dwa talerze dysków wirujące z prędkością 5400 obr./min. Napędy JAZ są zbliżone szybkością i wydajnością do dysków twardych jednak wolniejsze od SyJeta aż o 2,5 minuty.
Napędy LS
127 -120 jest typem wymiennej pamięci masowej, który umożliwia korzystanie z danych rejestrowanych na tradycyjnych 3,5" dyskietkach 720kB i 1,44 MB a oprócz tego pozwala zapisać do 120 MB informacji na specjalnie przystosowanych nośnikach, czyli 83 razy więcej niż na tradycyjnej dyskietce 3,5". Zwiększenie gęstości zapisu jest wynikiem zastosowania ulepszonych powłok magnetycznych, instalację głowicy magnetooptycznej, podniesienie szybkości obrotowej dysku do 720 obr./min oraz ponad 20-krotne zagęszczenie liczby ścieżek (2490 ścieżek na cal). Maksymalna szybkość przekazu danych wynosi 250 kB/s. Szczególne znaczenie ma możliwość ładowania systemu z superdyskietki, dzięki czemu LS-120 może być jedynym napędem zamontowanym w PC. W Windows 95 (OSR 2) i NT 4.0 zintegrowano już mechanizmy obsługi napędu LS-120. SuperDisk zwykle jest bezkonkurencyjny w przenośnych pecetach. Napędy HiFD
128 współpracują zarówno ze zwykłymi dyskietkami FDD, jak też ze specjalnymi nośnikami HiFD, zezwalając na zapis do 200 MB danych na jednym nośniku wymiennym. Napęd działa z prędkością obrotową 3600 obr./min i umożliwia transport danych z przepływnością 3,6 MB, a więc o wiele szybciej niż u najbliższych konkurentów pamięci z wymiennymi nośnikami. Uzyskano to dzięki prowadzeniu głowicy na poduszce powietrznej, w technologii stosowanej do tej pory wyłącznie w dyskach stałych (sztywnych). Napęd ten jest godny uwagi i zastosowania w bibliotekach, gdzie istnieje potrzeba nie tylko wyższej wydajności ale i pojemności. Nośniki optyczne CD
129 są wynikiem zwiększonego zapotrzebowania na pojemność pamięci dyskowej. Wyróżnić można wśród nich: płyty przeznaczone wyłącznie do odczytu (CD-ROM
130) oraz płyty zapisywalne (CD-R
131 , CD-RW
132 ,). Płyty zapisywalne CD, a w szczególności płyty jednokrotnego zapisu CD-R o krótszym czasie dostępu (70- 95 ms) do informacji niż napędy taśmowe, są dobrym sposobem składowania dużej liczby danych, zwłaszcza że ich zawartość na potrzeby archiwizacji nigdy nie powinna ulegać zmianie. Użytkowa wielkość danych cyfrowych zgromadzonych na jednej płycie CD wynosząca standardowo dla wszystkich typów około 650 MB (ok. 150 tys. stron maszynopisu), mimo iż zajmuje zaledwie kilka procent pojemności kasety współczesnego streamera taśmowego, to stanowi ponad 60 % całej zarejestrowanej na płycie informacji cyfrowej. Pozostała cześć danych to synchronizacja, sposoby formatowania, nagłówki, kodowanie danych, kody odczytu błędów i inne cechy zapewniające wysoką niezawodność odczytu. Nośniki magnetooptyczne DVD
133 są najmłodszą, najbardziej obiecującą specyfikacją dysków optycznych, która zaowocowała dużą pojemnością pojedynczego nośnika (4,7-17 GB), możliwością stosowania technologii w różnych systemach (tylko odczyt, zapis jednokrotny, zapis i odczyt wielokrotny), zgodność z wcześniej istniejącymi rozwiązaniami optycznymi (CD-ROM, CD-R, CD-RW). Dyski DVD stosowane do archiwizacji danych są głównie przeznaczone do składowania plików dźwiękowych, obrazów, filmów i video ale także, i do archiwizowania dużych zbiorów danych tekstowych. Zapewniają odpowiednie bezpieczeństwo informacji (odporność na zanieczyszczenia, pole magnetyczne i temperaturę) oraz natychmiastowy dostęp, co w przypadku dostępu do archiwów danych w bibliotece jest wymagane i konieczne. Wymienne dyski twarde zamontowane w wyjmowanych kieszeniach są interesującym rozwiązaniem do archiwizacji przede wszystkim ze względu na łatwość obsługi. Jednak istotną przeszkodą w uczynieniu ich idealnym rozwiązaniem jest wysoka cena archiwizacji wynikająca z potrzeby posiadania dysku wymiennego o pojemności przynajmniej równej pojemności stałego dysku twardego.
7.2.4. Biblioteka sieciowa - system i serwer archiwizacji.
Systemy archiwizacji danych są niezbędne przy każdej większej instalacji sieciowej. Dobrze zaprojektowany i skonfigurowany system archiwizacji opierający się na wspólnym funkcjonowaniu co najmniej trzech elementów związanych z procesem składowania (zautomatyzowana biblioteka danych, hierarchiczne oprogramowanie systemu zarządzania zasobami, serwera lub stacji roboczej dla tego typu oprogramowania) musi spełniać następujące wymagania:
- zapewniać, że dane na kopii zapasowej są identyczne z oryginalnymi danymi;
- przygotować kalendarz różnych rodzajów archiwizacji, które sam będzie wykonywać;
- współpracować z urządzeniami umieszczonymi w odrębnych miejscach konfiguracji sieciowej;
- prowadzić inwentaryzację kopii zapasowych w systemie i pozwolić administratorowi odszukać ręcznie lub automatycznie za pomocą znaczników czasowych pliki, zbiory spełniające odpowiednie kryteria, oraz samoczynnie je usuwać z archiwum;
- zapewnić możliwość odtworzenia dowolnego stanu danych z przeszłości. Zrzut danych może bowiem przebiegać prawidłowo, system komunikuje, że na taśmę zrzucane są kopie danych a w rzeczywistości nie został wgrany żaden bajt danych.
Serwerem archiwizacji może być dowolny komputer pracujący pod kontrolą systemu operacyjnego Unix , Novell czy Windows (serwer lub stacja robocza firm: HP, Sun, DEC, itp.), wyposażony w styk sieciowy do konfigurowania LAN i interfejsy (większą ilość SCSI) przeznaczone do efektywniejszego kontaktu ze zautomatyzowanymi bibliotekami o wymaganej przepływności. Serwer winien posiadać dodatkową szybką pamięć dyskową (podręczna pamięć cache dla archiwizowanych zbiorów) o pojemności kilku procent całkowitej pojemności obsługiwanej biblioteki oraz mieć zaimplementowane oprogramowanie zarządzające oparte są o hierarchiczną obsługę pamięci masowej HSM
134 , która polega na automatycznym przenoszeniu mało używanych lub wcale nie używanych plików z głównego medium pamięciowego na media wtórne - o większym czasie dostępu, ale tańsze w zakupie i eksploatacji. Użytkownik natomiast ma wrażenie, że posiada dostęp do nieograniczonych rozmiarów pamięci w sieci bez zamartwiania się o brak miejsca na swoim dysku lokalnym lub sieciowym. Plik zostaje przeniesiony po 30-dniowym okresie nie używania na dysk magnetooptyczny a następnie może wrócić do pamięci podstawowej. Jeżeli nie jest używany przez następne 30 dni wówczas system może go przenieść na taśmę magnetyczną a użytkownikowi ciągle będzie się wydawać, że plik zapisany jest na dysku magnetooptycznym i nic poza niewielkim opóźnieniem w czasie dostępu nie zdradzi, że zawartość jego znajduje się na innej pamięci masowej. System archiwizacji HMS nie jest jednak idealnym rozwiązaniem z tego względu, że operuje na wszystkich plikach danych i nie ma możliwości migracji jedynie fragmentu nie używanej bazy. Ponadto w wielu systemach istnieje przenoszenie z powrotem na dysk główny plików o takich rozmiarach, że nie mieszczą się na nim oraz problem archiwizacji plików o tych samych nazwach a następnie ich wyszukaniu w zbiorach archiwalnych. Większość jednak obecnych systemów archiwizacji dobrze radzi sobie z tymi problemami. Zasadniczym elementem jest zautomatyzowana biblioteka lub zespół bibliotek o mieszanych technologiach rejestrowania danych. Obecnie zalecanymi dla bibliotek sieciowych, są: sprawdzone i przetestowane narzędzie archiwizacji lokalnej o czasie dostępu mierzonym w minutach - Autoloader - automatyczne biblioteki taśmowe stosowane w serwerach i stacjach roboczych tychże sieci lub Jukebox - automatyczne biblioteki dysków magnetooptycznych (kilkaset płyt dysków optycznych z pojemnością łączną terabajtowych pamięci o czasie dostępu w pojedynczych sekundach). Na uwagę wśród optycznych bibliotek zasługują: CDR100 mieszcząca 100 płyt, o maks. pojemności do 65 GB danych i czasie dostępu poniżej 9 s, Mercury - 150 płyt, o łącznej pojemności 100 GB danych i czasie dostępu do danych nie przekraczającym 6 sekund oraz Satellite mieszczący 75 płyt, o łącznej pojemności 10 GB danych i dostępie poniżej 2,5 sekundy.
Na zakończenie rozważań o archiwizacji należy zwrócić uwagę, że Ci, którzy przyjdą po nas, będą z pewnością bezradni wobec pisanych świadectw naszej cywilizacji. Bowiem czym zajmować się będą historycy i archeologowie w przyszłości, gdy pisemnym świadectwem naszej kultury będą: papier, karty perforowane, dyskietki, taśmy magnetyczne i CD-ROM-y? Niektórzy twierdzą, że zapiski z naszych czasów żyją tylko przez chwilę i zgasną razem z nami a dzisiejsze standardy są ofiarami jutrzejszego postępu technicznego. Odkodowanie cyfrowych zapisków z naszych czasów będzie natomiast za 500 lub 1000 lat nie lada wyzwaniem dla archeologów, którzy będą musieli znaleźć odpowiednie urządzenia w zakamarkach muzeów, bez gwarancji, że będą one działały. "Lata dziewięćdziesiąte mogą okazać się najsłabiej udokumentowaną dekadą XX wieku"
135 i dlatego tylko "dzięki konsekwentnej, systematycznej opiece nad zbiorami jesteśmy w stanie bez trudu odczytać wszystkie nasze, nawet 25-letnie dane".
136
Początek strony |
Spis treści |
Poprzednia strona |
Następna strona
|
|
|
|
|