|
|
Warto wiedzieć
Mirosława Mocydlarz
Udostępnianie informacji naukowej na nośnikach elektronicznych
Rozdział 6.
Projekt udostępniania pełnotekstowych baz danych w bibliotece naukowej.
6.1. Wyszukiwanie informacji w bibliotekach elektronicznych w bazach pełnotekstowych.
Wyszukiwanie informacji, które polega na lokalizacji i uzyskaniu informacji z miejsca przechowywania, jest jedną z podstawowych funkcji baz danych realizowaną przez każdego użytkownika. W nowoczesnych bibliotekach elektronicznych wyszukiwanie dokumentów elektronicznych realizowane jest za pomocą systemu bibliotecznego wykorzystującego standard MARC lub za pomocą standardowej wyszukiwarki internetowej (Internet Explorer czy Netscape Communicator). W powyższych przypadkach jak i przy wyszukiwaniu informacji na stronach wydawców używa się słów kluczowych: nazwiska autora lub tytułu, roku wydania, itp. Elementy mogą być łączone operatorami boolowskimi. Istnieje jednak inne rozwiązanie przy pomocy metadanych zwanych "danymi o danych" zawierających informacje o formie i treści dokumentów elektronicznych. Umożliwiają wyszukiwanie większych zestawów informacji (dokumentów elektronicznych) w "cyber-przestrzeni" oraz ułatwiają zorganizowanie i zarządzanie informacją znajdującą się w WWW. Najczęściej stosuje się format metadanych, którego inicjatorem są bibliotekarze - Dublin Core Metadata Element Set (DC). Utworzony został dla dokumentów tekstowych w Web (patrz Tabela 6.1.). Część elementów jest wykorzystywanych także w przeszukiwaniu baz bibliograficznych. Niektóre służą do zapisu danych technicznych a inne informują kto posiada prawa do danego materiału.
Tabela 2. Schemat elementów Dublin Core.
|
Zawartość |
Własność intelektualna |
Dookreślenie |
|
Tytuł - nazwa dokumentu |
Twórca - osoba pierwotnie odpowiedzialna za stworzenie dokumentu |
Data - data udostępnienia dokumentu w obecnej formie |
|
Opis - tekst opisujący treść dokumentu |
|
Źródło - ciąg znaków do jednoznacznej identyfikacji dokumentu |
Współtwórca - osoba o wkładzie istotnym ale wtórnym w treść dokumentu |
Format - format danych w dokumencie do identyfikacji oprogramowania oraz czasu sprzętu potrzebnego do wyświetlenia i działania na dokumencie |
|
Język - język w którym napisany jest dokument |
|
Relacja - powiązania miedzy danym dokumentem a innymi istniejącymi samodzielnie |
Własność - opis praw autorskich, copyright, itp. |
Identyfikator - ciąg znaków (numer) używany do indywidualnej identyfikacji dokumentu |
|
Miejsce i Czas - czasowe i/lub przestrzenne charakterystyki dokumentu |
Istnieją różnice pomiędzy stosunkiem metadanych i opisywanym źródłem elektronicznym a stosunkiem rekordu katalogowego i opisywaną książką. W skomputeryzowanej bibliotece istnienie opisu dokumentu nie wpływa na użytkowanie samego dokumentu: rekord zawiera opis bibliograficzny oraz lokalne dane biblioteki (sygnatura). Dopiero znając sygnaturę można dotrzeć do dokumentu poprzez odrębny system udostępniania, co często zresztą nie odbywa się bez pomocy personelu. Zwykle jest niezbędna obecność użytkownika w bibliotece w momencie odbierania i zwrotu pozycji. Zupełnie inaczej wygląda w przypadku metadanych i dokumentów elektronicznych. Same są częścią infrastruktury informacyjnej, pozwalając na bezpośredni dostęp do opisywanego dokumentu z dowolnego miejsca przyłączonego do sieci. Dotarcie więc do dowolnego elementu powoduje możliwość bezpośredniego i natychmiastowego dotarcia do treści samego dokumentu. W skutek takich zmian bibliotekarze mogą porzucić swoje przyzwyczajenia do lokalnych katalogów opisujących lokalnie przechowywane dokumenty i zastosować standardy wykorzystania metadanych.
6.2. Skanowanie.
Użytkownicy bibliotek naukowych wymagają, aby materiały w nich dostępne były w formie elektronicznej. Nie zdają sobie jednak sprawy, że większość dokumentów, książek, które były publikowane i wydawane kilka lat wcześniej, nie miały swojego odpowiednika elektronicznego. Dzisiaj sytuacja przedstawia się nieco inaczej, gdyż większość wydawców oferuje informacje naukowe zarówno w formie tradycyjnej - drukowanej, jak i w formie cyfrowej. Zbiory już istniejące trzeba jednak poddać digitalizacji (zeskanować). Istnieją pewne reguły dotyczące skanowania tekstu:
- oryginały muszą być skanowane z możliwie największą rozdzielczością, dla tekstu całkowicie jednak wystarczy rozdzielczość 300 dpi;
- skanowanie tekstu wymaga 100% dokładności skanowania;
- jeżeli oryginał czarno-biały jest przejrzysty, można skanować go w trybie odcieni szarości (10 bitów) co znacznie zmniejsza rozmiar pliku graficznego i przyspiesza pracę;
- jeśli tło jest kolorowe lub obłożone teksturą albo napisy są w innym kolorze niż czarny dokument należy skanować w trybie kolorowym;
- skanując znaki z grubej książki lub magazynu należy zadbać o to, żeby znaki znajdujące się blisko środka były jak najmniej zniekształcone;
- skanowany tekst musi być dobrze wypoziomowany, tj. kartka dokumentu musi być prosto włożona do skanera. Wprawdzie dzisiejsze programy radzą sobie ze złym ułożeniem dokumentu za pomocą specjalnych mechanizmów poziomujących ale powoduje to wydłużenie przetwarzania tekstu i zwiększa ryzyko pojawienia się błędów.
6.3. Rozpoznawanie tekstu - systemy typu OCR, przykładowe aplikacje dostępne na polskim rynku.
O bibliotece bez papieru - bibliotece, w której liczba dokumentów papierowych jest ograniczona mówi się od kilku lat. Aby przejść na formę elektroniczną dokumentów należy dokumenty w formie tradycyjnej - papierowej odpowiednio skonwertować i przekształcić do postaci cyfrowej, możliwej do odczytania przez komputer. Służą do tego celu programy do rozpoznawania tekstu, które w sposób podobny do człowieka, analizują odczytywane znaki za pomocą sztucznych sieci neuronowych, oraz w trudniejszych przypadkach. umieszczone w aplikacjach systemy ekspertowe samodzielnie dyskutują uzyskane przez siebie wyniki badań. Kontrolę nad przebiegiem takiej konferencji "sprawuje" min. logika rozmyta. Jednak mimo tak dynamicznego rozwoju zarówno Internetu jak i publikacji elektronicznych, papier, który wynaleziony został prawie dwa tysiące lat temu, nadal jest najchętniej i najczęściej używaną formą do przekazywania słowa pisanego. To powoduje, że istnieje problem przenoszenia informacji z papieru na język zrozumiały dla komputera. Do rozwiązania tego problemu stosowane są systemy typu OCR
85. Są to technologie optycznego rozpoznawania znaków. W ramach OCR możemy wyróżnić ICR
86 , którego zadaniem jest inteligentne rozpoznawanie znaków polegające na wykorzystaniu algorytmów rozpoznawania wzorowanych na ludzkim sposobie percepcji. Mechanizm OCR umożliwia rozpoznawanie tekstu pisanego konkretną i ustaloną czcionką natomiast ICR - tekstu pisanego dowolną czcionką, także ręcznie. OCR/ICR to technika zamiany graficznej formy napisu na odpowiadający mu ciąg znaków. Aplikacje OCR wykorzystują skomplikowane algorytmy zbudowane na bazie skomplikowanych teorii naukowych. Od 25 lat funkcjonują algorytmy rozpoznawania tekstu drukowanego. Początkowo był to mechanizm sprzętowy, który polegał na porównaniu pojedynczych znaków z ich odpowiednikami na liście znormalizowanych wzorców OCR-A czy OCR-B, zwany Matrix Matching. Jeśli odczytany obraz znaku jest zgodny z obiektem wzorcowym, przechowywanym w pamięci w postaci pikseli, to jest mu przyporządkowany odpowiedni kod ASCII i uznaje się dany znak za rozpoznany. Jednak wystarczyły tylko niewielkie odstępstwa kształtu czcionki od zdefiniowanego wzorca i niemożliwe było rozpoznanie tekstu. Technika "porównania ze wzorcem" w 1975 r. została zastąpiona techniką "analizy cech charakterystycznych"
87 , która polegała na poszukiwaniu charakterystycznych kształtów krzywizn, elementów kolistych między liniami podłużnymi, i poprzecznymi. Technika nosi nazwę omnifont
88 (rozpoznanie wszystkich typów czcionek i wielkości pisma). Lata osiemdziesiąte to gwałtowny rozwój teorii sztucznych sieci neuronowych
89 wykorzystywanych jako klasyfikatory, które na podstawie dostarczonej na wejście informacji o matematyczno-geometrycznych cechach znaku podejmowały decyzję o tym, jaki to znak. Niewątpliwą zaletą jest uczenie się sieci neuronowej w skutek czego wystarczyło przeszkolić taką sieć prezentując jej zestaw czcionek, a ta sam wyrabiała wiedzę na temat kształtów poszczególnych znaków. Architektura sieci neuronowej służącej do rozpoznawania tekstu jest wzorowana na strukturze połączeń, które występują w tej części mózgu człowieka, która jest odpowiedzialna za przetwarzanie informacji wizualnej. W sieciach neuronowych proces przetwarzania informacji podlega tzw. logice rozmytej
90 , w której występują pojęcia "fałszu" i "prawdy", pojęcia pośrednie między tymi terminami jak "częściowa prawda" czy "nie do końca fałsz" bowiem systemy eksperckie bazujące na logice rozmytej programów OCR wykorzystują fakt, iż mózg ludzki może rozwiązywać efektywnie i sensownie problemy nawet, wtedy gdy nie ma jednoznacznie określonych parametrów. Rezultatem jest wykorzystanie możliwości tworzenia wielu wariantów rozpoznawania, przy czym każdy algorytm może postawić różne hipotezy, oceniane przez dodatkowych ekspertów, co do prawdopodobieństwa wystąpienia każdego z tych wariantów. Wynikiem jest graf, który opisuje wszystkie możliwe sekwencje znaków z prawdopodobieństwem wystąpienia znaku na żądanej pozycji. Mając wiele wariantów pojawia się jednak problem, który wariant wybrać. Najodpowiedniejszą metodą wspomagającą wybór jest zastosowanie metody analizy językowej jednak nie opartej na przeglądaniu słownika (zawodzi w przypadku wyboru wariantu słowa, np. "miła" czy "mila" - oba słowa występują w języku polskim a więc prawdopodobieństwo wystąpienia znaku "l" czy "ł" będzie równe 50%). Pomocna w tej sytuacji byłaby metoda analizy językowej oparta na analizie gramatycznej. Jednak jak do tej pory nie została zrealizowana w jakimkolwiek komercyjnym czy nawet akademickim systemie OCR w odniesieniu do języka polskiego. Dzisiaj techniki sieci neuronowych, logiki rozmytej wykorzystywane są jedynie wtedy gdy inne techniki zawodzą. Jest to spowodowane długim czasem wyliczania stanu sieci a obecne aplikacje OCR wykorzystują zazwyczaj kilka algorytmów aby jak najwierniej odtworzyć oryginalny tekst w postaci elektronicznej. Do rozpoznawania czytelnego, drukowanego pisma używany jest zazwyczaj algorytm omnifont lub jego bardziej rozbudowane wersje - do tekstu gorszej jakości, do którego rozpoznania można również zastosować sieci neuronowe. W każdej aplikacji stosowane są nadal proste algorytmy porównania ze wzorcem. Proces konwersji tradycyjnej formy: kartka, faks, slajd na formę cyfrową: plik ASCII, bazy danych, arkusza kalkulacyjnego, edytora tekstu można podzielić na następujące etapy: wstępne przetworzenie i ustalenie obrazu (Preprocessing) - automatycznie wykrywana i konfigurowana orientacja teksu na stronie, program sprawdza min. czy wydruk nie został włożony do skanera "do góry nogami", czy jest to druk czarno-biały czy negatyw (białe litery na czarnym tle) czy wydruk kolorowy nawet w 32-bitowej palecie kolorów. Często również na tym etapie następują tzw. filtracje usuwające drobne kropki i zakłócenia, co wpływa na jakość rozpoznawania znaków; - optyczne rozpoznanie znaków OCR:
identyfikacja i wyróżnienie bloków znaków, i obiektów nie będących znakami, tj. ilustracji oraz ustalenie kolejności ich przetwarzania;
rozpoznawanie pojedynczych znaków, zwane często "ekstrakcją właściwości" - identyfikacja znaków, analiza kształtów i porównanie właściwości z zestawem reguł, które opisują fonty (pochyłe, ozdobne, pogrubione, itp.);
rozpoznanie całych słów - porównanie zestawu znaków ze słowami znajdującymi się w słowniku danego języka powoduje skrócenie rozpoznawania tekstu i zmniejszenie ilości błędnych rozpoznań;
korekta efektów rozpoznawania - korektorem może być sam użytkownik lub program, którego odpowiednie mechanizmy rozpoznawania przystępują do tzw. głosowania w przypadku wątpliwości co do znaków, wybierany jest wariant z większą liczbą głosów;
formatowanie dokumentu wyjściowego - aplikacja OCR zapisuje dokument w jednym z dostępnych formatów wyjściowych, np.: *.txt, *.doc, *.xls, itd.;
Na poprawność rozpoznawania tekstu wpływa także jakość dokumentu oryginalnego, rodzaj nośnika, na którym został on wydrukowany a także skomplikowanie danego języka, znaków narodowych, wielkość i krój czcionki, i w końcu jakość skanera, i rozdzielczość skanowania. Im jest ona większa tym lepsza jest jakość zeskanowanego dokumentu, co powoduje jednak zwiększenie rozmiaru pliku wyjściowego (patrz Rozdział 6.2.).
Proces konwersji - rozpoznawania tekstu trwa w zależności od jakości wydruku, wielkości czcionki, typu komputera, jakości oprogramowania typu OCR od 30 sekund do kilku minut na jedną stronę.
Na rynku polskim można znaleźć wiele programów OCR. Niektóre z nich sprzedawane są w cenie detalicznej a inne dołączane są przy zakupie skanera. Wśród nich na plan pierwszy jednak wysuwa się Recognita Plus w wersji 5.0 węgierskiej firmy o nazwie Recognita, wchodzącej w skład koncernu Caerre Fine Reader 4.0 Professional PL rosyjskiej firmy ABBYY.
Recognita Plus 5.0 rozpoznaje aż sto czternaście języków, opartych na alfabecie łacińskim, greckim i cyrylicy, a także większość języków krajów Europy Wschodniej i Południowo-Wschodniej. Menu oraz system pomocy programu jest w pełni spolszczone. Program pozwala również na rozpoznawanie i zachowanie dokumentu w pliku z zachowaniem układu stron oryginał (zarówno tabele jak i rysunki) a także współpracuje z aplikacjami biurowymi dając tym samym użytkownikowi duży wybór formatów wyjściowych, np. MS Word i Excel a także jako pliki: *.txt, *.html czy *.pdf. Aplikacja korzysta ze złożonych algorytmów matematycznych: analiza konturów, zintegrowanej analizy językowej czy technologii samoupewniania. Zawiera unikatową funkcję ręcznej korekty tekstu, podczas której użytkownik sam może korzystać ze słownika ortograficznego. Aplikacja oferuje sześć poziomów dokładności i kontroli prędkości rozpoznawania tekstu niezależnie od kroju czcionki, rozmiaru, w przedziale od 6 do 72 punktów. Ponadto Recognita Plus 5.0 oferuje dla osób z wadą wzroku program do konwersji dokumentów brajlowskich i głośnego ich odczytywania za pomocą komputera, który wyposażony jest w syntezator mowy z odpowiednim oprogramowaniem. Jest to wielka zaleta albowiem do tej pory ludzie z upośledzeniem wzroku nie mogli korzystać z zasobów biblioteki, a nawet nie dane im było odczuć jak potężne znaczenie dla rozwoju człowieka mają dostępne informacje naukowe.
Fine Reader 4.0 Professional PL będący nowoczesnym, 32-bitowym programem OCR/ICR, pracującym w systemach Windows 95/98/NT wykorzystujący technologię MMX jest najpoważniejszym rywalem programu Recognita Plus 5.0 mimo, że rozpoznaje tylko pięćdziesiąt trzy języki i dysponuje dwudziestoma słownikami, w tym języka polskiego. Podobnie jak Recognita program umożliwia zapisanie danych wyjściowych w różnych formatach, posiada prosty w obsłudze interfejs użytkownika niedostępny jednak w języku polskim. Ma możliwość rozpoznawania polskich znaków diakrytycznych. Aplikacja ta podczas rozpoznawania tekstu, zarówno drukowanego w różnych układach graficznych jak i tabel czy kodów kreskowych, pisma ozdobnego robi mało błędów. Według przeglądu i testów programów dokonanej w czasopiśmie komputerowym PC World Komputer z miesiąca lutego 2000 roku wynika, iż przy maksymalnym poziomie dokładności rozpoznawania złej jakości dokumentu faksowego (papier termoczuły, pożółkły w wyniku działania światła słonecznego z dwoma tłustymi plamami o średnicy około 3 cm i 1,5 cm) najlepsze wyniki osiągnął program Recognita Plus 5.0 - 73,8%, tuż za nim Fine Reader 4.0 Professional PL - 73,2% poprawności. W ogólnej klasyfikacji
91 również na pierwszym miejscu znalazł się program Recognita ze względu na liczbę rozpoznawanych języków, możliwość współpracy z dużą liczbą różnych skanerów, opcję rozpoznania tekstu z map bitowych zapisanych w nieskompresowanych plikach z grafiką rastrową (tiff, bmp lub pcx) i otwierania dokumentów zapisanych w formacie jpeg oraz na dodatkowe oprogramowanie dla osób z upośledzeniem wzroku oraz najniższą cenę i łatwość zakupu na rynku polskim a także ze względu na niewielkie wymagania sprzętowe: komputer z procesorem nawet 486DX i 16 MB pamięci RAM (dla tekstów składających się z wielu krojów czcionek - wymagania: komputer z procesorem Pentium i z 32 MB pamięci RAM). W klasyfikacji brane były także i inne aplikacje jak: Readiris 5.0, TextBridge Pro 9.0. Programy te jednak w testach nie osiągnęły takich efektów rozpoznawania tekstu jak powyżej wymienione. Na zakończenie rozważań na temat programów OCR należy podkreślić, że nikt jeszcze, jak do tej pory, nie napisał programu doskonałego ale dzisiejszym aplikacjom niewiele brakuje już do doskonałości.
6.4. Systemy biblioteczne.
W latach 70-tych po raz pierwszy podjęto próby przeniesienia informacji początkowo naukowych (dane bibliograficzne) do komputerowych baz danych. Efektem takich działań było powstanie pierwszych systemów bibliotecznych umożliwiających przetwarzanie składowanych danych. Obecnie na rynku jest wiele systemów bibliotecznych od najprostszych do najbardziej rozbudowanych. Który jest najlepszy? Który wybrać? Na to pytanie nie można odpowiedzieć jednoznacznie, ponieważ wszystko zależy od specyfiki danej biblioteki i jej potrzeb. Można jednak zauważyć pewną tendencję. Małe biblioteki oraz biblioteki szkół prywatnych używają do dnia dzisiejszego proste systemy, które wprowadzane były na rynek Polski jako pierwsze, tj. Sowa, Lech, Apin. Biblioteki natomiast wyższych szkół państwowych - z reguły biblioteki gromadzące wiele zasobów, wdrażają lub przechodzą na zintegrowane systemy biblioteczne jak Horizon, VTLS czy Aleph, które także wykorzystują tę część informacji, jaka charakteryzuje katalogowaną literaturę. Cechą komputerowych zintegrowanych systemów bibliotecznych jest to, że każdy opis dokumentu - rekord wprowadzany jest wyłącznie raz do zbioru a wykorzystywany może być w różnych modułach: gromadzenia, katalogowania, kontroli czasopism, wypożyczania, udostępniania.
System Sowa jest głównym produktem firmy Sokrates-Software wdrożonym w ponad 500 bibliotekach. Jest on pakietem programów, które wspomagają biblioteki i umożliwiają zautomatyzowanie procesów bibliotecznych.: gromadzenia zbiorów, katalogowania materiałów bibliotecznych, wyszukiwania informacji w zbiorach biblioteki poprzez sieć lokalną i zbiorach innych bibliotek poprzez Internet oraz udostępnianie zbiorów: wypożyczanie, rezerwowanie i zamawianie.
Katalogowanie materiałów bibliotecznych to zastąpienie tradycyjnej metody katalogowania przez tworzenie katalogów komputerowych zbudowanych z tzw. rekordów. Informacja zawarta w rekordzie jest podzielona na pola i podpola a zbiór reguł rozmieszczania informacji w tychże polach, i podpolach rekordu nazywa się formatem, który określa możliwości wyszukiwania, wymiany i przedstawiania danych. Ponieważ większość systemów pozwala na dowolne zaprojektowanie formatu danych, dlatego też podejmowane są próby ujednolicania formatów.
System Sowa przyjął własny, czytelny format wprowadzania i prezentacji danych książkowych zgodny z drugim poziomem szczegółowości określonym przez PN. Istnieje jednak możliwość pobierania danych zapisanych w wielu innych formatach, także USMARC (patrz Rozdział 6.5.). Jest prostym i sprawdzonym narzędziem, które nie wymaga zatrudnienia specjalistów - informatyków ale może być obsługiwane już po krótkim szkoleniu, dlatego też powinien być stosowany w bibliotekach bez tradycyjnych, rutynowych rozwiązań organizacyjnych.
System Lech jest także prostym systemem bibliotecznym, który ma podobne możliwości, jak opisany powyżej, system Sowa. Jednak o systemie tym mówi się, że jest narzędziem niedoskonałym. Jego niedoskonałość wynika bowiem z niekompatybilności z innymi systemami, co z kolei sprawia, że jest on niewidoczny w Internecie, a i w systemie lokalnym bibliotek bywają kłopoty z wejściem do katalogów bibliotecznych. Poza tym nie jest wyposażony w moduł katalogowania czasopism oraz rzadko możliwe jest uaktywnienie modułu zamawiania, co jest istotnym utrudnieniem dla bibliotekarzy j i użytkowników.
Komputerowy system zintegrowany Aleph może automatyzować nie tylko pojedyncze biblioteki, ale również lokalną sieć bibliotek (np. bibliotekę główną i wszystkie biblioteki wydziałowe i instytutowe danej uczelni zlokalizowane nawet w różnych punktach miasta). W ramach takiej sieci, biblioteki mogą posiadać wspólne bazy danych, katalogi lub zarządzać swoimi katalogami samodzielnie, decydując o formie opisów książek, czasopism i innych dokumentów, wyborze sposobów wyszukiwania w katalogu dokumentów także pełnotekstowych, zasadach udostępniania zbiorów, itd. Biblioteki mogą współpracować ze sobą na poziomie wypożyczalni. System jest systemem elastycznym w pełni spolszczonym z dokumentacją w języku polskim. Ponadto system oferuje pracę w trybie Klient-Serwer a integralną część stanowi Graficzny Interfejs Użytkownika
92 , który wykorzystuje hipertekst i zapewnia użytkownikowi przyjazne środowisko pracy. Aleph posiada własny serwer WWW umożliwiający korzystanie z katalogu poza biblioteką wraz z możliwością złożenia zamówienia oraz własny serwer Z39.50 (patrz Rozdział 6.6.). Format danych systemu spełnia wymagania ISO 2709 oraz standardu USMARC. VTLS - Virginia Tech Library System jest elastycznym zintegrowanym oprogramowaniem bibliotecznym, który stosuje się do międzynarodowych norm i pozwala na obsługę multimediów. Wykorzystuje strukturę rekordu opartą na formacie USMARC. Wszystkie katalogi bibliotek VTLS-owych są dostępne w sieci Internet. Wadą wprowadzenia systemu VTLS w polskich bibliotekach była konieczność opracowania kartotek haseł wzorcowych, które "służą do kontroli haseł opisu, stanowiąc specyficzny filtr dla błędnie sformułowanych haseł oraz ułatwiają modyfikację haseł i ich aktualizację. Kartoteki haseł wzorcowych odwzorowują relacje między hasłami wzorcowymi (ujednolicona nazwa danej osoby, ciała zbiorowego, ujednolicony tytuł, itd.) oraz hasłami wzorcowymi i formami odrzuconymi, dzięki czemu powiększają możliwości wyszukiwawcze systemu. Ich istotą jest jednoznaczność, standaryzacja i spójność danych zawartych a kartotece a tym samym danych wprowadzanych do katalogu. Kartoteki wzorcowe łączą w jeden spójny system hasła opisu bibliograficznego i hasła charakterystyki rzeczowej, gwarantując spójność.
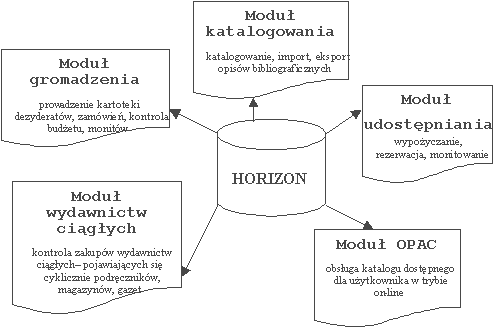
93 System jest wykorzystywany w wielu polskich bibliotekach szkół wyższych państwowych zwłaszcza na terenie Warszawy czy Krakowa. Horizon jest systemem informacyjnym stworzonym przez amerykańską firmę Ameritech Library Services a funkcjonującym w kilkudziesięciu placówkach na terenie kraju. System od maja 1996 roku jest wdrażany między innymi w bibliotekach państwowych szkół wyższych miasta Poznania. Horizon wykorzystuje system zarządzania bazą danych Sybase i pracuje w architekturze Klient-Serwer, dzięki której umożliwia swobodny dostęp do innych systemów bibliotecznych oraz zasobów sieciowych (przeglądarki, systemy baz pełnotekstowych, zasoby multimedialne). Ma również wbudowany protokół Z39.50 a dodatkową zaletą jest obsługa opisu formatu danych: MAB, UNIMARC, USMARC. Horizon składa się z pięciu modułów (Rysunek 1.), z których każdy odpowiada za inne operacje wykonywane na rekordach danych.
Rysunek 1. Moduły systemu Horizon.
Wybór komputerowego zintegrowanego sytemu bibliotecznego, który wynika z daleko idącego procesu informatyzacji bibliotek naukowych i wynikającej z niego potrzeby konwersji, wymaga określenia organizacji i specyfiki biblioteki akademickiej oraz potrzeb użytkowników i bibliotekarzy. Powinien być jednak dokonany w taki sposób aby użytkownikowi zapewniał właściwy komfort w korzystaniu z biblioteki a bibliotekarzom ułatwiał pracę. Nowoczesna biblioteka akademicka, której zadaniem jest gromadzenie zasobów nie tylko z własnych źródeł ale i z źródeł innych bibliotek oraz przede wszystkim udostępnianie informacji naukowej na nośnikach elektronicznych winna wybrać komputerowy, nowoczesny i także elastyczny zintegrowany system biblioteczny zgodny z normami międzynarodowymi (Aleph, Horizon, VTLS), o ujednoliconym formacie opisu danych zgodnym ze standardem USMARC (Aleph, Horizon, VTLS), system spełniający wymagania stawiane przez biblioteki lokalne o księgozbiorach nie przekraczających 3000 pozycji jak i przez biblioteki poza granicami naszego kraju i konsorcja (poprzez sieć Internet), które zawierają miliony rekordów (Horizon), zawierający wersję spolszczoną i dokumentację w języku polskim (Horizon). Ponadto system taki powinien łatwo dostosowywać się do pracy na różnych platformach sprzętowo-programowych jak system Horizon (UnixTM, DEC Open VMSTM, Novell Netware, Microsoft Windows NTTM, Sun Solaris, SunOSTM, IBM OS/2) oraz umożliwiać odbywanie transakcji w czasie rzeczywistym, co w dowolnym momencie zapewni użytkownikowi dostęp do aktualnych informacji i umożliwić równoległą pracę z różnymi jego modułami, która pozwoli na szybkie przełączenie między nimi (Horizon).
6.5. Format USMARC rekordu bibliograficznego dla książki.
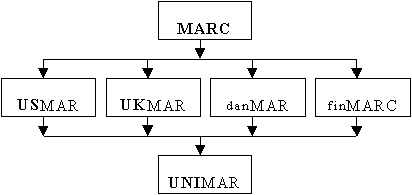
Format MARC
94 jest formatem opartym na idei indeksowanych pól i podpól zmiennej długości. Jednym z jego wariantów (Rysunek 2.), które zostały opracowane na potrzeby bibliotek całego świata (stąd przedrostki w nazwach) jest format rekordu bibliograficznego USMARC, który stanowi standard reprezentowania informacji bibliograficznej w postaci odczytywanej przez maszynę cyfrową. Ponieważ istnieje wiele różnych wariantów formatu MARC, IFLA
95 - Międzynarodowa Federacja Stowarzyszeń Bibliotekarskich podjęła próbę standaryzacji wariantów formatu MARC tworząc format UNIMARC. Format USMARC został opracowany dla różnego rodzaju dokumentów spełniając rolę nośnika informacji bibliograficznej na temat następujących typów dokumentów: tekstów drukowanych i manuskryptów - książek, publikacji, listów, itp.; plików komputerowych - informacji zakodowanych w sposób umożliwiający ich przetwarzanie na komputerze lub innej podobnej maszynie, włączając pliki, rekordy danych i programy do ich przetwarzania; wydawnictw ciągłych - pełnotekstowych materiałów publikowanych co pewien okres czasu: podręczniki, czasopisma, gazety, kodeksy, itp.; muzyki i obiektów wizualnych - nagrań dźwiękowych i muzycznych, zapisu nutowego, filmów, grafiki dwuwymiarowej i trójwymiarowej, itp.;
dokumentów multimedialnych i dokumentów będących hybrydami powyższych.
Rysunek 2. Format MARC.
Standard USMARC został zdefiniowany także dla różnych typów danych: bibliograficznych (tytuł, nazwiska autorów, przedmiot dyskusji, dziedzina, itp.), zasobów (holding) - miejsca przechowywania danej pozycji bibliograficznej, danych kartoteki haseł wzorcowych, informacje klasyfikacyjne - do przechowywania i rozwoju schematów klasyfikacji, informacje dodatkowe (rekordy przechowujące informacje na temat zdarzeń, programów, usług umożliwiające integrację tych rekordów z rekordami innych typów w katalogach z publicznym dostępem).
Format rekordu bibliograficznego powinien umożliwić zapis wszystkich danych, które charakteryzują opisywany przezeń dokument. W formacie USMARC wyróżniono około tysiąca pól i podpól, w których można zapisać informacje na temat dokumentu dowolnego typu. Format rekordu dotyczy także struktury rekordu (implementacja standardów międzynarodowych i lokalnych, np.: ANSI Z39.2, ISO 2709 czy spełnia wymagania polskiej normy PN-N-09015:1984), oznaczeń pól i podpól rekordu (kody i konwencje oznaczeń jednoznacznie identyfikujące poszczególne pola rekordu i ułatwiające dostęp do tych pól), oraz danych (większość informacji bibliograficznych, które powinny znaleźć się w opisie dokumentu została zdefiniowana zewnętrznie, pozostałe informacje definiuje format USMARC).
Od stycznia 1994 r. naukowe biblioteki akademickie na terenie naszego kraju, które wykorzystują oprogramowanie Horizon, VTLS i Aleph stosują format USMARC rekordu bibliograficznego zgodnie z instrukcją Format USMARC rekordu bibliograficznego wydawnictwa ciągłego (Warszawa 1994) oraz Format USMARC rekordu zasobu (Sopot 1994). Standard USMARC nie jest jeszcze w całości ustalony. Trwają nad nim prace a wszelkie zmiany proponowane są przez Komitet Doradczy MARC
96 . Po zatwierdzeniu zmian przez Biuro Rozwoju Sieci i Standardów MARC
97 informacje o nich są udostępniane jako publikacje rozpowszechniane przez Służbę Rozpowszechniania Wydawnictw Biblioteki Kongresu.
98
6.6. Protokół komunikacji Z39.50.
Z39.50 jest międzynarodowym standardem komunikacji między systemami komputerowymi, używanymi głównie w bibliotekach i aplikacjach w celu dostępu do informacyjnych baz danych. Wzajemna komunikacja między częściami jest realizowana w oparciu o architekturę Klient-Serwer. Najbardziej typowy schemat procesu wymiany danych między klientem a serwerem podczas poszukiwania bazy danych przebiega następująco:
użytkownik OPAC
99 - katalogu dostępnego on-line dla użytkownika, dokonuje wyboru bazy danych, którą należy przeszukać; użytkownik katalogu OPAC wprowadza zapytanie, żądanie wyszukania danych rekordów; oprogramowanie OPAC wysyła żądanie szukania danych do klienta Z39.50 (Z-klient) zwykle zintegrowanego z lokalnym systemem bibliotecznym; Z-klient przekłada pytanie na język zapytań Z39.50 a następnie wysyła do zlokalizowanego Z-serwera w celu dalszego przeszukiwania (przed wykonaniem jakiejkolwiek pracy Z-klient i Z-serwer muszą wynegocjować usługi i pytania, które są legalne a które nie); Z-serwer przekłada żądanie wyszukania rekordów z języka Z39.50 na język zapytań przeszukiwanej bazy danych a następnie wysyła do niej żądanie i otrzymuje w odpowiedzi odpowiednią grupę rekordów; Z-serwer wysyła poszukiwane rekordy do Z-klienta, który po kolei przekazuje je do katalogu OPAC odpowiedzialnego za prezentację wyszukanych rezultatów przez użytkownika.
Do najważniejszych, realizowanych funkcji i zalet obecnej wersji protokołu komunikacji Z39.50 należą:
- obsługa formatu rekordu MARC;
dostęp do rekordów bibliotecznych niezależnie od rodzaju systemu, w którym są one przechowywane;
- standard w przeszukiwaniu katalogów bibliotecznych w trybie on-line;
możliwość wyszukiwania kilku obiektów w tym samym czasie przy użyciu tylko jednego klienta wyszukiwania zadającego te same lub różne pytania do przeszukiwanej bazy danych;
wyszukiwanie funkcji włączając zaawansowane funkcje logiczne (boolowskie);
możliwość użycia rozszerzonych usług (zamawianie dokumentów, wysyłanie rekordów od klienta do bazy danych, dzielenie schematów przeszukiwania dla innych użyć, zdolność do magazynowania wyszukanych rekordów i rezultatów w celu użycia w przyszłości, możliwość definiowania okresowych wyszukiwań i zamawiania kopii oraz modyfikacji bazy danych), które są usługami dodatkowymi do standardowego wyszukiwania;
wykonanie dodatkowych funkcji włączając kontrolę dostępu, zdolność do rejestrowania dostępu użytkownika;
- zdolność do tworzenia wirtualnego wspólnego katalogu.
Od roku 1984 prace na rozwojem protokołu Z39.50 trwają. Istnieje rzeczywista potrzeba rozwoju i standaryzacji powiązanych rozszerzonych usług, i implementacji użycia protokołu z automatycznym systemem bibliotecznym. Obecnie jednak protokół Z39.50 nadal jest używany jako narzędzie wyszukiwania.
Początek strony |
Spis treści |
Poprzednia strona |
Następna strona
|
|
|
|
|